[Algorithms | C++] Insertion sort : 삽입 정렬
[Algorithms | C++] Insertion sort : 삽입 정렬
삽입 정렬(Insertion sort) 알고리즘 개념
- 손안의 카드를 정렬하는 방법과 유사하다.
- 새로운 카드를 기존의 정렬된 카드 사이의 올바른 자리를 찾아 삽입한다.
- 새로 삽입될 카드의 수만큼 반복하게 되면 전체 카드가 정렬된다.
- 자료 배열의 모든 요소를 앞에서부터 차례대로 이미 정렬된 배열 부분과 비교 하여, 자신의 위치를 찾아 삽입함으로써 정렬을 완성하는 알고리즘
- 매 순서마다 해당 원소를 삽입할 수 있는 위치를 찾아 해당 위치에 넣는다.
삽입 정렬(Insertion sort) 알고리즘의 예제
배열에 8, 5, 6, 2, 4가 저장되어 있다고 가정하고 자료를 오름차순으로 정렬해 보자.

- 1회전: 두 번째 자료인 5를 Key로 해서 그 이전의 자료들과 비교한다.
- Key 값 5와 첫 번째 자료인 8을 비교한다. 8이 5보다 크므로 8을 5자리에 넣고 Key 값 5를 8의 자리인 첫 번째에 기억시킨다.
- 2회전: 세 번째 자료인 6을 Key 값으로 해서 그 이전의 자료들과 비교한다.
- Key 값 6과 두 번째 자료인 8을 비교한다. 8이 Key 값보다 크므로 8을 6이 있던 세 번째 자리에 기억시킨다.
- Key 값 6과 첫 번째 자료인 5를 비교한다. 5가 Key 값보다 작으므로 Key 값 6을 두 번째 자리에 기억시킨다.
- 3회전: 네 번째 자료인 2를 Key 값으로 해서 그 이전의 자료들과 비교한다.
- Key 값 2와 세 번째 자료인 8을 비교한다. 8이 Key 값보다 크므로 8을 2가 있던 네 번째 자리에 기억시킨다.
- Key 값 2와 두 번째 자료인 6을 비교한다. 6이 Key 값보다 크므로 6을 세 번째 자리에 기억시킨다.
- Key 값 2와 첫 번째 자료인 5를 비교한다. 5가 Key 값보다 크므로 5를 두 번째 자리에 넣고 그 자리에 Key 값 2를 기억시킨다.
- 4회전: 다섯 번째 자료인 4를 Key 값으로 해서 그 이전의 자료들과 비교한다.
- Key 값 4와 네 번째 자료인 8을 비교한다. 8이 Key 값보다 크므로 8을 다섯 번째 자리에 기억시킨다.
- Key 값 4와 세 번째 자료인 6을 비교한다. 6이 Key 값보다 크므로 6을 네 번째 자리에 기억시킨다.
- Key 값 4와 두 번째 자료인 5를 비교한다. 5가 Key 값보다 크므로 5를 세 번째 자리에 기억시킨다.
- Key 값 4와 첫 번째 자료인 2를 비교한다. 2가 Key 값보다 작으므로 4를 두 번째 자리에 기억시킨다.
C++로 구현한 삽입 정렬 (Insertion sort)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
void DoubleList::InsertSort() {
Node *Current(NULL);
for (int i = 1; i < CountNode(); i++) {
Current = ArrangeNode(i);
for (int j = i; j > 0; j--) {
if (Current->getData() < Current->getLlink()->getData()) {
Node *tmp = Current->getLlink();
if (tmp == Head) {
Head = Current;
if (Current == Tail) {
Tail = tmp;
}
else if (Current != Tail) {
Current->getRlink()->setLlink(tmp);
}
}
else if (Current == Tail) {
Tail = tmp;
tmp->getLlink()->setRlink(Current);
}
else {
tmp->getLlink()->setRlink(Current);
Current->getRlink()->setLlink(tmp);
}
Current->setLlink(tmp->getLlink());
tmp->setRlink(Current->getRlink());
Current->setRlink(tmp);
tmp->setLlink(Current);
Current = tmp;
}
Current = Current->getLlink();
}
}
}
삽입 정렬(Insertion sort) 알고리즘의 특징
- 장점
- 안정한 정렬 방법
- 레코드의 수가 적을 경우 알고리즘 자체가 매우 간단하므로 다른 복잡한 정렬 방법보다 유리할 수 있다.
- 대부분위 레코드가 이미 정렬되어 있는 경우에 매우 효율적일 수 있다.
- 단점
- 비교적 많은 레코드들의 이동을 포함한다.
- 레코드 수가 많고 레코드 크기가 클 경우에 적합하지 않다.
삽입 정렬(Insertion sort)의 시간복잡도
시간복잡도를 계산한다면
- 최선의 경우
- 비교 횟수
- 이동 없이 1번의 비교만 이루어진다.
- 외부 루프: (n-1)번
- Best T(n) = O(n)
- 비교 횟수
- 최악의 경우(입력 자료가 역순일 경우)
- 비교 횟수
- 외부 루프 안의 각 반복마다 i번의 비교 수행
- 외부 루프: (n-1) + (n-2) + … + 2 + 1 = n(n-1)/2 = O(n^2)
- 교환 횟수
- 외부 루프의 각 단계마다 (i+2)번의 이동 발생
- n(n-1)/2 + 2(n-1) = (n^2+3n-4)/2 = O(n^2)
- Worst T(n) = O(n^2)
- 비교 횟수
정렬 알고리즘 시간복잡도 비교
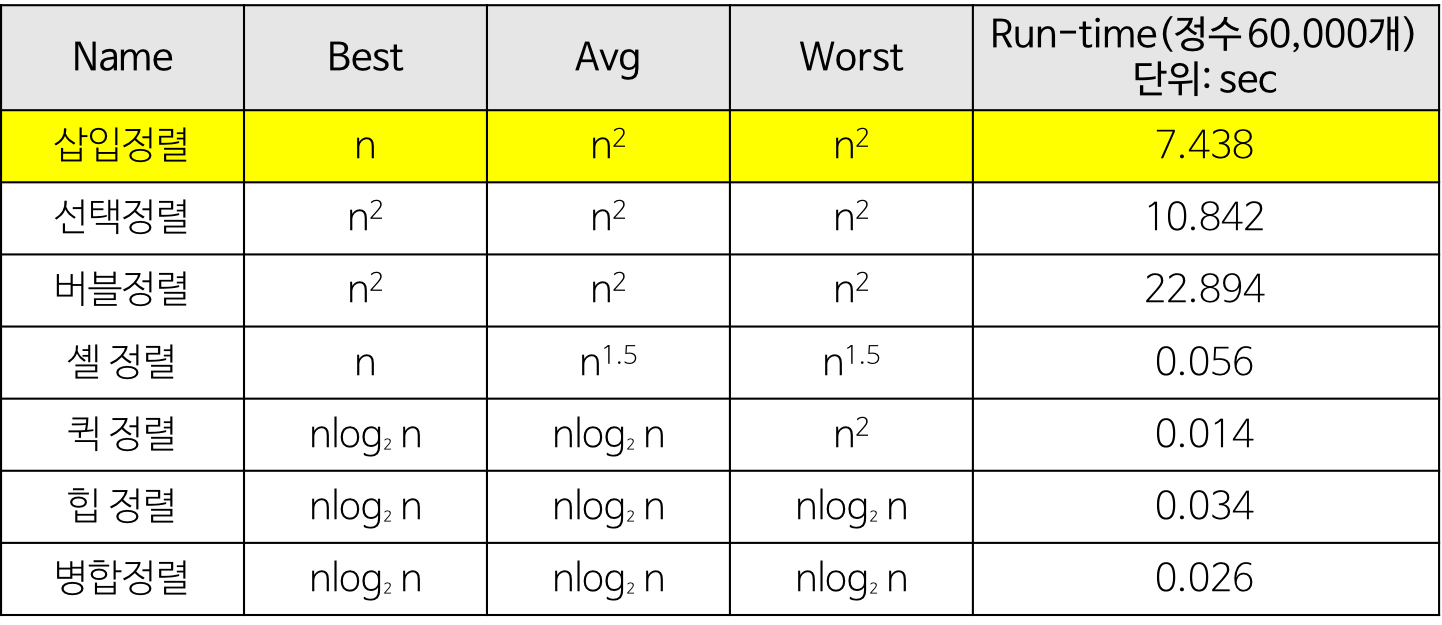
- 단순(구현 간단)하지만 비효율적인 방법
- 삽입 정렬, 선택 정렬, 버블 정렬
- 복잡하지만 효율적인 방법
- 퀵 정렬, 힙 정렬, 합병 정렬, 기수 정렬
삽입 정렬 - 위키백과 참고
This post is licensed under CC BY 4.0 by the author.