Compilation Process
- 컴파일 과정은 프로그램을 만드는 데 있어서 반드시 알아야 하는 내용은 아니지만 이 과정을 머리속에 담고 있는 개발자는 앞으로 무수히 부딪히게 될 많은 문제나 오류들을 이해하는데 훨씬 큰 이점을 얻게 될 것이다.
Compile 과정이란?
- 컴퓨터 프로그램의 개발은 코드 작성(프로그래밍)부터 시작된다.
- 이렇게 작성된 코드는 사용자(개발자)가 컴퓨터가 수행해 주기를 원하는 내용을 기술한 것이지만, 컴퓨터가 이해할 수 있는 문법(언어)이 아닌 사용자가 이해할 수 있는 문법이다.
- 따라서 작성된 코드는 컴파일(Compile) 과정을 거쳐 컴퓨터가 이해할 수 있는 언어로 변환되며, 컴파일된 파일을 오브젝트 파일(Object File)이라고 부른다.
- 일반적으로 하나의 프로그램은 여러 개의 오브젝트 파일과 공용 라이브러리로 조합이 되며, 하나의 컴퓨터가 실행할 수 있는 프로그램을 완성화기 위한 작업을 링킹(Linking)이라고 부른다.
- 결국 코드를 컴파일 과정과 링킹 과정을 거치면 사용자가 실행할 수 있는 실행 파일(ex. EXE 파일)이 생성된다.
- 완성된 실행파일을 사용자가 실행(Execute)하게 되면 컴퓨터는 해당 프로그램의 내용을 메모리에 적재(Load)시키고 내용에 따라 프로그램을 수행하게 된다.
- 이러한 일을 수행하는 프로그램을 로더(Loader)라고 한다.
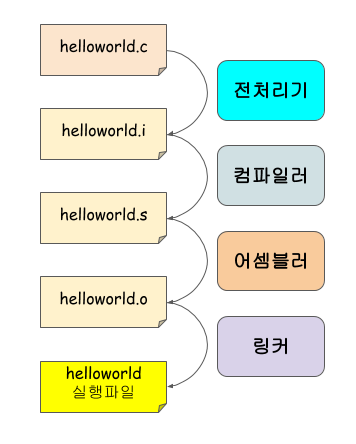
- 개발자가 작성한 코드는 위의 과정을 거쳐 실행 가능한 바이너리 파일(Binary File)로 만들어진다.
- 이렇게 만들어진 실행파일을 실행하면 바이너리 파일의 내용들이 주기억장치(Ram)로 적재(Load)되어 시스템에서 동작하게 된다.
전처리기(Preprocessor)란?
- 컴파일 하기 직전에 처리하는 컴파일러의 한 부분이다.
- 전처리기가 하는 일은 #define처럼 치환의 역할을 하기도 하고, 디버깅에도 도움을 주며 헤더파일의 중복 포함도 방지해준다.
- 전처리기에서는 몇가지 지시자들을 처리하게 된다.
- 이 지시자들은 #라는 기호로 시작한다.
**#include**
- 가장 흔히 볼 수 있는 전처리기이다.
- 해당 파일을 찾아서 컴파일러가 그 파일이 마치 현재 컴파일하는 소스 코드에 포함되어 있는 것 같이 해준다.
- <>는 표준 헤더 파일일 경우에 설정되어 있는 폴더에서 헤더 파일을 찾으며, ““는 그 외 폴더에서 찾을 수 있는데 최우선으로 현재 프로젝트 폴더에서 찾게 된다.
#define
- define문은 여러 경우에 사용될 수 있는데 일반적으로 문자열 대치에 사용된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
-------------------------------
#define MAX 512
int Arr[MAX];
int Arr[512];
-------------------------------
#define MAX
#ifdef MAX
cout << "Max is defined!" << endl;
#else
cout << "Max is not defined!" << endl;
#endif
-------------------------------
#ifdef MAX
#elif defined(MIN)
#else
#endif
-------------------------------
#if defined(MAX)
#elif defined(MIN)
#else
#endif
-------------------------------
// [관련된 주요 전처리기 명령어]
#ifdef
#ifndef
#undef
#if defined
#if !defined
#elif
#else
#endif
포함감시(Inclusion Guard)
- 여러 개의 헤더 파일(.h 또는 .hpp)과 구현 파일(.c 또는 .cpp)들이 있을 경우 헤더 파일이 중복 포함되는 경우가 많다. 포함 감시 기능은 만드는 모든 헤더 파일에 적용하도록 하자.
1
2
3
4
5
6
7
#ifndef FILENAME_H
#define FILENAME_H
// 여기에 헤더 파일의 모든 내용을 넣는다.
#endif
-------------------------------
#include "filename.h"
#include "filename.h" // 두 번째 헤더 파일이 포함될 때 #ifndef가 거짓이 되어 헤더 파일이 포함되지 않는다.
- 포함 감시 기능을 이용하여 두 번째 헤더 파일이 포함될 때 #ifndef가 거짓이 되어 헤더 파일이 포함되지 않는다.
- FILENAME_H 부분은 관례상 파일명을 이용해서 이렇게 명명한다.
_FILENAME_H또는__FILENAME_H__등 잘 사용되지 않는 문자열을 파일 이름을 사용해서 만드는 것이다.
매크로 함수(Macro Function)
- 매크로 함수도 전처리기로 흔히 사용된다. 다만 디버깅이 힘들다는 단점 때문에 점점 사용되지 않고 있다고 들었다.
- 특히, C++의 경우 엄격한 형 검사를 하게 되는데 매크로 함수를 사용하게 되면 그 기능을 사용할 수 없으니 피해야 한다.
- C++ 사용자는 매크로 함수보다는 Template 또는 inline 함수를 사용해야 한다.
1
2
3
4
5
6
7
8
9
10
11
#define CUBE(x) ((x)*(x)*(x))
int x, y;
y = CUBE(x);
-------------------------------
int x, y;
y = (x)*(x)*(x);
문자열 조작
1
2
3
4
5
6
7
8
9
10
#define SAY(x) printf(#x)
SAY(Hello, world!);
// 위와 같이 식별자 앞에 #을 붙이게 되면 자동으로 "x"와 같이 ""로 둘러싸준다.
-------------------------------
printf("Hello, world!");
문자열 결합
1
2
3
#define Print(x) Print ## x
// ##은 두 개의 문자열을 결합해 준다.
// Pirnt(One)을 사용하면 PrintOne이라는 문자열로 대치되고 Print(Two)는 PrintTwo라는 문자열로 대치된다.
ASSERT()
- 대부분의 컴파일러는 ASSERT() 매크로를 가지고 있다.
1
2
3
4
5
6
7
8
9
10
#ifndef DEBUG
#define ASSERT(x)
#else
#define ASSERT(x) \
if(!(x))\
{ \
printf(#x); \
printf("is Null on line %d in file %s", __LINE__, __FILE__); \
}
#endif
- 위 코드의 위에 #define DEBUG를 포함하면 #define ASSERT(x)는 아무 일도 하지 않고, DEBUG가 정의되지 않으면 그 아래 함수가 정의된다.
즉, 디버그일 때만 코드가 생성되고 릴리즈시에는 코드가 생서되지 않게 할 수 있는 것이다.
- 여러 줄이 필요할 때는 **가 사용되었다는 것에 유의하자.
내장 매크로
컴파일 시에 컴파일러가 미리 정의하고 있는 매크로들이 있다.
__DATE__: 컴파일하는 날짜__TIME__: 컴파일하는 시간__LINE__: 현재 컴파일하고 있는 줄 번호__FILE__: 현재 컴파일하고 있는 파일의 이름을
error
- 컴파일러는 이 명령을 만나게 되면 해당 메시지를 출력하고 컴파일을 중지한다.
- C++ 컴파일러에서만 동작하게 하는 다음 코드를 참조하자.
1
2
3
4
5
#if !defined(__cplusplus)
#error C++ compiler required.
#endif
// __cplusplus는 C++ 컴파일러일 경우에 정의되는 내장 매크로이다.
pragma
- #pragma는 컴파일러마다 고유하게 사용할 수 있는 명령어이다. 따라서 그 문법은 컴파일러마다 다르고 그 종류도 많다.
- #pragma once 같은 경우 위의 포함 감시 기능을 컴파일러가 알아서 해준다. 즉, 한 번 include 된 헤더 파일은 중복해서 포함되지 않도록 컴파일러가 처리해 준다.
컴파일 과정 - 전단부 (Front-End)
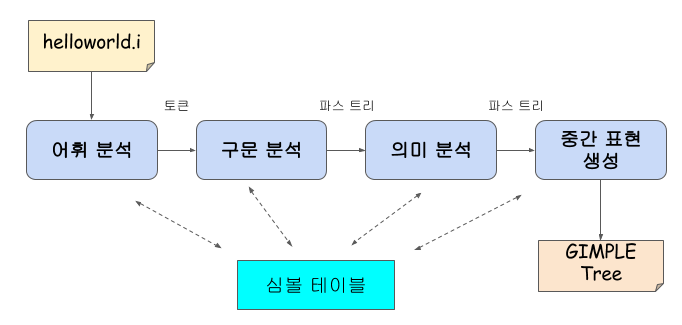
- 전단부에서는 언어 종속적인 부분을 처리한다.
- 이 단계에서는 C, C++, Java 등의 다른 언어로 작성된 코드들이 각각 다른 모듈에 의해 처리되며, 소스코드가 올바르게 작성되었는지 분석하고, 중단부에 넘겨주기 위한 GIMPLE 트리 (소스코드를 트리 형태로 표현한 자료구조)를 생성하는 일을 수행한다.
- 어휘 분석 : C 소스코드를 의미가 있는 최소단위(토큰 : Token)으로 나눈다.
- 구문 분석 : 토큰으로 파스 트리(Parse Tree)를 만들면서 문법적 오류를 검출한다.
- 의미 분석 : 파스 트리를 이용해 문법적 오류는 없지만 의미상 오류가 있는지 검사한다.(함수의 매개변수를 잘못 사용했다거나 변수의 자료형(Data Type)이 불일치 하는 것 등을 검사)
- 중간 표현 생성 : 언어 독립적인 특성을 제공하기 위해 트리 형태의 중간표현(GIMPLE Tree)을 생성한다.
컴파일 과정 - 중단부 (Middle-End)
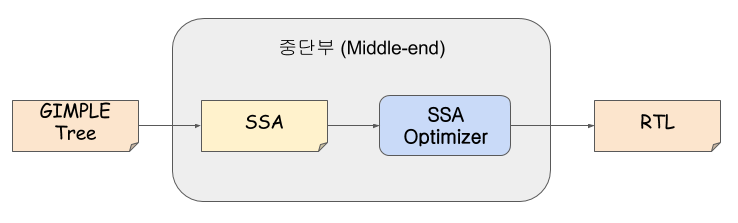
- 중단부에서는 전단부에서 넘겨 받은 GIMPLE Tree를 SSA(Static Single Assignment)형태로 변환한 후에 아키텍쳐 비종속적인 최적화를 수행한 후 최종적으로 후단부에서 사용하는 RTL(Register Transfer Language : 고급 언어와 어셈블리 언어의 중간 형태)을 생성한다.
아키텍쳐 비종속적인 최적화란 서로 다른 CPU 아키텍쳐에 구애받지 않고 공통적으로 수행할 수 있는 최적화를 말한다. 중단부에서는 SSA 기반으로 최적화를 수행한다.
- 최적화가 왜 중요한가?에 대해서 설명하자면, 개발자들이 작성한 프로그램이 한번 컴파일 되고 나면 다시 컴파일하기 전까지 변경이 불가능하다. (물론 리버싱이라는 기법이 있다고 합니다만 여기에서는 논외로 하겠습니다… 잘 몰라서리…) 그렇기 때문에 최적화를 수행함으로써 컴파일 시간이 오래 걸릴지라도 프로그램의 수행 속도를 향상시켜 전체 시스템 성능의 효율을 지속적으로 높여주기 때문이다.
- SSA 기반 최적화는 크게 지역 최적화, 전역 최적화, 루프 최적화로 나눌 수 있는데, 최적화에 관한 내용은 굉장히 방대하여 여기에서는 간략하게 ‘이런 과정들이 있다’ 정도로만 알고 있으면 되겠다.
- 최적화가 완료되면 후단부에서 최적화에 사용하기 위해 RTL(Register Transfer Language)구조로 변환한다.
컴파일 과정 - 후단부 (Back-End)
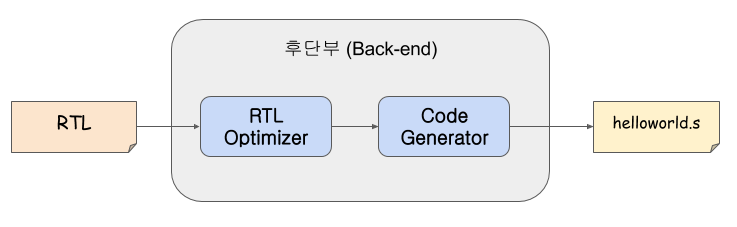
- 후단부에서는 RTL Optimizer에 의해 아키텍쳐 비종속적인 최적화와 함께 아키텍쳐 종속적인 최적화가 수행된다.
- 아키텍쳐 종속적인 최적화는 각 프로그램 내의 명령어 중 아키텍쳐별로 좀 더 효율적인 명령어로 대체해 성능을 높이는 작업과 같이 아키텍쳐 특성에 따라 최적화를 수행하는 것을 말한다.
- 이렇게 최적화를 마치게 되면 Code Generator 어셈블리어로 구성된 .s 파일이 만들어지게 됩니다.
컴파일 과정 - 어셈블 과정
- 컴파일이 끝난 어셈블리 코드는 어셈블러에 의해 기계어로 어셈블됩니다.
- 어셈블러에 의해 생성되는 목적코드(helloworld.o) 파일은 어셈블된 프로그램의 명령어(Instruction)과 데이터(Data)가 들어있는 ELF 바이너리 포맷(Binary Format) 구조를 갖는다.
- 다음 단계인 링킹에서 링커가 여러 개의 바이너리 파일을 하나의 실행 파일로 묶기 위해서 각 바이너리의 정보를 효과적으로 파악하기 위해서(명령어와 데이터의 범위 등) 일정한 규칙을 갖게 형식화 해놓은 것이다.
컴파일 과정 - 링킹 과정
- 어셈블리에 의해 ELF 포맷의 목적코드 파일들이 만들어지면 이제 링커의 차례이다.
- 링커는 오브젝트 파일들과 여러분의 프로그램에서 사용된 표준 C 라이브러리, 사용자 라이브러리들을 링크(Link)를 합니다.
- printf() 함수나 scanf() 등의 표준 C 라이브러리 함수들은 여러분이 직접 구현하지 않아도 미리 컴파일이 되어 있기 때문에 링크하는 과정만 거치면 사용할 수 있다. (표준 C 라이브러리는 별도로 명시하지 않아도 자동으로 링크됩니다.)
- 이렇게 링킹 과정이 끝나면 실행 가능한 실행 파일이 만들어진다.
Byte code languages (JAVA, C#….)
바이트코드는 가상기계어 개념으로 생각하시면됩니다. JAVA도 알다시피 컴파일을 합니다. 하지만 컴파일의 결과물이 실행파일이 아닌 class라는 바이트 코드 파일이죠. 이를 JRE(Java Runtime Environment), CLI(common language infrastructure)라는 인터프리터가 한줄씩 실행하여 동작합니다. CLI는 윈도우의 닷넷 계열 실행환경입니다. 이를 통해 컴파일러 즉 바이트 코드 생성기는 C++ 컴파일러와 같지만 실행하는 JVM, CLI등의 인터프리터를 OS나 플랫폼 별로 만들어 Java라는 언어가 플랫폼 독립적으로 실행되는 것입니다.
‘보통 자바는 C++보다 엄청 느리다.’ 라고하는데 이는 단정짓기 어려운 사실입니다. JRE 즉 바이트코드를 실행하는 JVM 은 바이트코드를 인터프리터 형식으로 실행하는데 이떄 C++ 처럼 기계어로 번역되어 실행합니다 또한 JVM(Java Virtual Machine)은 GC(Garbage Collector)를 튜닝할수 있기 때문에 어떤때는 C++보다 빠를수가 있습니다.
하지만 분명한 사실은 자바 같은 바이트 코드언어는 직접적인 하드웨어 제어가 불가능합니다. 소스 코드가 직접적으로 하드웨어에 반영되는게 아니기 때문이죠. 그래서 포인터나 Win32 API 같은 수준의 System call을 사용할수 없는 것입니다. 그러한 이유로 보안 관련 프로그램이나 극도의 optimization이 요구되는 프로그램에 C/C++등이 사용되는 것입니다.
결론은 ‘자바가 확실한건 C++보다 개발생산성이 뛰어나고 직접전인 하드웨어 제어는 불가능하다,’ 라는 점입니다.
- 컴파일
- Compiler에 의해서 java 소스 파일이 class파일로 바꾸어집니다.
- 이 과정은 C++ 컴파일 과정과 유사합니다 결과물이 어셈블리나 기계어가 아닌 바이트 코드라는 점이 다른것입니다.
- JRE안에서의 과정
- 먼저 바이트 코드가 유효한지 검사합니다.
- CLASS 파일을 JRE가 메모리에 적재시킵니다.
- Just In-Time Compiler(JIT)
- 이 기술은 바이트 코드 형태의 언어 실행 속도를 높이기 위한 기술로써 JRE에 포함된 JVM이 바이트 코드를 실행할 때 플랫폼별로 컴파일을 하는데 이 과정에서 실제 실행 코드가 기계어로 번역되어집니다.
- 실행
- 어떤 OS든 JAVA 코드가 같은 결과물을 내놓습니다.
- 즉, 자바의 플랫폼 독립은 같은 소스코드와 실행 결과를 말하는 것이며,
- 코드를 플랫폼 독립적으로 실행 시키기위해 OS별로 다른 방식의 JVM이나 JRE가 만들어집니다.
Interpreter languages (Javascript, Python, Ruby…)
인터프리터 언어는 컴파일 언어와 다르게 한줄씩 바로 언어를 번역해서 실행됩니다. C++은 소스 파일이 전체 컴파일되는 반면 인터프리터는 한줄씩 컴파일되어 실행됩니다. 그렇기 때문에 번역하는 과정에서 메모리가 훨씬 적게 소모되기 때문에 효율적입니다.
구글 크롬은 크로미늄이라는 오픈소스 프로젝트의 결과물입니다. 이 크로미늄은 오픈소스 이기 때문에 누구나 다운받아 빌드할수있습니다.
과연 시간이 얼마나 걸릴까요? 검색해본결과 적어도 1시간이상 걸린다고 합니다. 이는 크로미늄은 C/C++로 작성되어 있기 때문인데요. 컴파일 과정에 필요한 메모리와 시간이 인터프리터에 비해 엄청나게 높고 오래걸립니다.
만약 파이썬으로 작성되어있다면 2시간은 커녕 길어야 5분일것입니다. 이것이 컴파일과 인터프리터의 차이입니다.
인터프리터는 즉시 실행될수있다는 장점때문에 실시간 분석이나 대화형으로 프로그래밍이 가능합니다. 여러분이 아시는 파이썬은 데이터마이닝, 빅데이터, 등의 연구 분야의 주로 사용되는 언어입니다.