[Kubernetes] Grafana Loki
[Kubernetes] Grafana Loki
Loki
- Loki는 로그 전체 TEXT가 아닌 metadata만 인덱싱하는 방식을 취한다.
- 이런 최소 인덱싱 접근 방식은 다른 솔루션보다 적은 저장 공간이 필요함을 의미한다.
- Loki를 위해 만들어진 로그 수집 도구인 Promtail 또는 OpenTelemetry를 통해 로그를 가져와 로그를 저장한다.
- 이후 Grafana에서 LogQL이라는 쿼리 언어를 통해 로그를 검색하게 된다.
- 또한 경고 규칙을 설정하여 Prometheus Alertmanager로 경고를 보낼 수 있다.
- “Like Prometheus, but for logs”
Prometheus가 metric을 시계열 데이터로 저장하기 위해 사용된다면 Loki는 log 데이터를 저장하기 위해 사용된다.
- Loki는 log data를 효율적으로 보관하기 위해 최적화된 데이터 저장소이다.
- 다른 logging system과 다르게 Loki index는 label에서 작성되며 원래 log message는 색인화되지 않는다.
- Prometheus가 저장과 polling을 담당한 것과 달리 Loki는 저장을 담당하고 application에서 push를 해주는 역할을 해주는 agent가 필요하다.
- Promtail agent는 Loki를 위해 설계되었지만 그 외에 다른 많은 agent(FluentD, LogStash 혹은 기타 서비스 애플리케이션)가 Loki와 원활하게 통합된다.
- Loki는 stream을 indexing 한다.
- 각 steam은 고유한 label set과 연결된 log 집합을 식별한다.
- label의 quality set은 간결하고 효율적인 query 실행을 허용하는 index 생성의 핵심이다.
- LogQL은 Loki의 query language이다.
Loki 특징
- log indexing을 위한 효율적인 memory 사용
- multi-tenancy
- LogQL - Prometheus의 query language인 PromQL과 유사하며, log data에서 metric을 생성하는 것이 용이함.
- Scalability - 단일 바이너리로 사용할 수도 있으나 component 별 microservice로 실행될 수도 있음
- Flexibility - 많은 agent가 플러그인을 지원
- Grafana 통합
Loki 저장소
- Loki는 chunk와 index라는 두 가지 유형의 데이터를 저장해야 한다.
- Loki는 별도의 stream으로 log를 수신하며 각 steam은 tenant ID와 label set으로 고유하게 식별된다.
- stream의 log 항목이 도착하면 chunk로 압축되어 chunk 저장소에 저장된다.
index는 각 steam의 label set를 저장하고 개별 chunk에 연결한다.
- index에 대해 다음 저장소가 지원
- Single Store (boltdb-shipper)
- Amazon DynamoDB
- Google Bigtable
- Apache Cassandra
- BoltDB
- chunk에 대해 다음 저장소가 지원
- Amazon DynamoDB
- Google Bigtable
- Apache Cassandra
- Amazon S3
- Google Cloud Storage
- FlieSystem
- Baidu Object Storage
- 기본 설정은 storage가 filesystem이며 Amazon S3의 경우 로컬에서 개발 시 minio를 사용할 수도 있다.
Loki 설정
설정 파일에 대한 자세한 내용
- https://grafana.com/docs/loki/latest/configuration/
- common 아래에 설정을 하면 전체가 공통으로 사용할 설정을 하게 된다.
- Loki는 component별 microservice로 구성할 수 있다.
- Loki의 component는 대략 아래와 같이 있다.
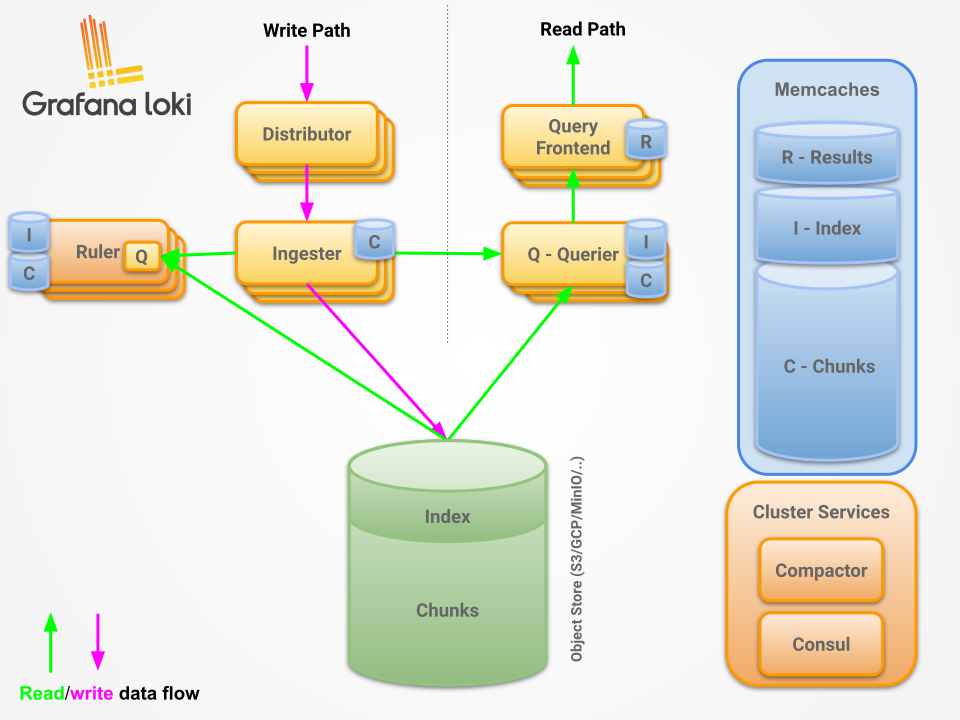
- Distributor : client가 수신하는 stream을 처리하는 역할, steam의 유효성을 확인하고 여러 ingester로 병렬로 전송을 적절하게 제어
- Ingester : storage에 log data를 저장하고 write path 및 read path의 memory 내 쿼리에 대한 log data를 반환
- Query frontend : query 발송의 API endpoint를 제공하는 선택적 서비스
- Querier : LogQL을 사용하여 query를 처리하고 ingester와 storage에서 log를 가져옴
Loki Helm Charts
- grafana/loki 관련된 Helm chart들을 살펴보면 대략 5가지 정도가 존재
- grafana/loki : 현재 Grafana Loki에서 중점적으로 관리 및 업데이트하고 있는 Helm chart
- grafana/loki-distributed : Microservice 형태로 Loki를 관리할 수 있도록 해주는 Helm chart
- Ingester, Querier, Index Gateway, Distributor, Query-Frontend, Ruler 등으로 구분되어 있음
- grafana/loki-simple-scalable : 현재 Deprecated 되었지만 Loki를 아주 간단하게 관리할 수 있도록 도와주는 Helm chart
- Write와 Read, Nginx gateway로만 구분되어 있다.
- grafana/loki-stack : 올인원 모놀리식 형태로 사용할 수 있는 Loki Helm chart
1. loki-stack
- “loki-stack” Helm 차트는 Loki를 단일 노드로 구성하여 배포하는 방법을 제공한다.
- 이는 기본적인 Loki 설치를 위해 사용되며, 로그 수집, 저장 및 검색을 단일 노드에서 처리한다.
- 이 단일 노드는 다수의 컨테이너로 구성되어 Loki 서버, Prometheus, Grafana 및 Prometheus 메트릭 저장소를 모두 단일 클러스터에 배포한다.
- 이 단순한 배포 방식은 개발 및 테스트 용도로 적합할 수 있다.
2. loki-distributed
- “loki-distributed” Helm 차트는 Loki를 분산 환경에서 배포하기 위해 설계되었다.
- 이 차트는 Loki의 구성 요소들을 다수의 노드로 분산시키고, 데이터를 보다 효율적으로 처리하고 처리 능력을 확장할 수 있도록 도와준다.
- 분산된 Loki를 사용하면 대량의 로그를 처리하는 데 더 적합하며, 고가용성과 확장성을 갖추기 위해 다양한 구성을 가능하게 한다.
Architecture
- 핵심 개념
- Read Path와 Write Path : Loki는 로그 데이터 처리를 위한 읽기 경로(Read Path)와 쓰기 경로(Write Path)를 구분한다. 이러한 분리는 데이터 처리의 효율성을 극대화하며, 각 경로는 특정 작업에 최적화된 컴포넌트로 구성된다.
- Consistent Hash Rings : 클러스터 내에서 데이터를 균등하게 분배하고 고가용성을 보장하는 메커니즘이다. 이는 클러스터의 스케일링을 용이하게 하며, 데이터 샤딩과 복제를 통한 안정성을 제공한다.
- Multi-tenancy : Loki는 다중 테넌시를 지원하여, 하나의 Loki 인스턴스를 여러 사용자나 팀이 공유할 수 있게 한다. 이는 리소스의 효율적인 사용과 데이터 분리를 가능하게 한다.
Write Path: Distributor, Ingester
Distributor
- 클라이언트로부터 수신한 로그 데이터를 검증 후 Ingester에게 전달하는 역할을 담당한다. 여기서 클라이언트는 Promtail이 될 수도 있고 FluentD, LogStash 혹은 기타 서비스 애플리케이션 쪽 로그 라이브러리가 될 수도 있다.
- Distributor의 주요 기능 및 특징
- 유효성 검사(Validation) : Distributor는 수신된 스트림이 Grafana LGTM 사양에 부합하는지 첫 번째로 확인한다. 이는 데이터가 올바르게 처리될 수 있는지를 보장하기 위한 필수적인 과정이다.
- 전처리(Preprocessing) : 스트림의 레이블을 정렬하는 과정으로, 이를 통해 Loki는 데이터를 효율적으로 캐시하고 해시할 수 있다.
- 속도 제한(Rate limiting) : 테넌트별 최대 전송률을 설정하여, 들어오는 로그의 전송률을 제어할 수 있다. 이는 시스템의 안정성을 유지하는 데 중요한 역할을 한다.
- 전달(Forwarding) : 모든 유효성 검사와 전처리 작업을 마친 후, 데이터는 Ingester로 전달된다. Ingester는 최종적으로 데이터의 쓰기를 승인하며, 이 과정에서 replication_factor를 참고하여 데이터 손실 위험을 최소화하기 위한 복제본을 생성한다.
- replication_factor가 3이라면 Ingester 내에 3개의 복제본을 생성하도록 3개의 스트림을 전달한다.
- 해싱(Hashing) : Distributor는 일관된 해싱을 사용해 특정 스트림이 전달될 Ingester 인스턴스를 결정한다. 이는 데이터가 올바른 대상에게 전달되도록 한다.
- 쿼럼 일관성(Quorum consistency) : Distributor는 최소 절반 이상의 Ingester로부터 응답을 받기 전까지는 클라이언트에게 응답을 보류한다. 이는 Dynamo 스타일의 쿼럼 일관성을 통해 데이터의 신뢰성을 높인다.
- 이러한 과정과 특징들은 Distributor가 Grafana Loki에서 매우 중요한 역할을 수행하게 한다.
- 특히, stateless한 성격 덕분에, 작업을 Ingester로 쉽게 확장하고 오프로드할 수 있으며, DDos 공격으로부터 시스템을 보호할 수 있다.
- 또한 distributor는 내부에서 링 component를 사용하여 peers 사이에서 자신을 등록하고 총 active distributors를 얻는다. 이는 ingesters가 링에서 사용하는 것과는 다른 “키”이며 distributor의 자체 링 구성에서 비롯된다. 이는 Distributor의 효율성과 안정성을 더욱 높인다.
Ingester
- Distributor로부터 받은 로그 데이터를 메모리에 압축하여 chunks 단위로 저장하고 일정 시간 후 장기 저장소 백엔드(DynamoDB, S3, Cassandra 등)에 기록하는 역할을 담당한다.
Ingester는 로그 데이터를 장기 저장소 백엔드(예: DynamoDB, S3, Cassandra 등)에 저장하고, 필요 시 인메모리 쿼리를 통해 이 데이터를 빠르게 검색하는 역할을 한다.
- Ingester의 주요 기능 및 특징
- 수명 주기 관리 : Ingester 내에는 lifecycler라고 불리는 컴포넌트가 포함되어 있어, 해시 링을 통해 각 Ingester의 생명 주기를 관리한다. Ingester의 상태는 PENDING, JOINING, ACTIVE, LEAVING, 또는 UNHEALTHY 중 하나이다.
- chunk 처리 : 로그 스트림은 메모리 내에서 여러 ‘chunk’ 집합으로 관리되며, 설정 가능한 주기에 따라 장기 저장소 백엔드로 플러시된다. chunk는 용량에 도달하거나, 업데이트 없이 일정 시간이 지나거나, 플러시가 발생할 때 압축되고 읽기 전용으로 전환된다.
- 데이터 복제 : 갑작스러운 프로세스 종료나 충돌로 인해 아직 플러시되지 않은 데이터 손실을 방지하기 위해, Loki는 로그 데이터를 여러 Ingester에 복제한다(일반적으로 3개,replication_factor). 이는 데이터의 안정성과 가용성을 높인다.
- Timestamp Ordering : Loki는 설정을 통해 시간 순서가 뒤섞인 데이터 쓰기를 허용할 수 있다. 이러한 설정 없이는 Ingester가 순서대로 입력되는 로그 라인을 확인하고, 순서가 맞지 않는 경우 오류를 반환한다.
- 파일 시스템 지원 : Ingester는 BoltDB를 통해 파일 시스템에 쓰기를 지원하지만, queriers가 동일한 백엔드 저장소에 액세스해야 하고 BoltDB는 주어진 시간에 하나의 프로세스만 DB에 대한 잠금을 가질 수 있도록 허용하기 때문에 단일 프로세스 모드에서만 작동한다.
- 작동 방식
- 플러시 : 장기 저장소로의 플러시 과정에서, chunk는 테넌트, 레이블, 콘텐츠를 기반으로 해시되어 중복된 데이터의 백업 저장소 쓰기를 방지한다. 그러나 복제본 중 하나에 쓰기가 실패하면 여러 개의 서로 다른 chunk 객체가 생성될 수 있다.
- 이러한 기능과 특징들은 Ingester가 Grafana LGTM 아키텍처에서 중요한 역할을 수행하게 한다. 데이터의 안정적인 저장과 효율적인 검색을 보장하는 동시에, 시스템의 전반적인 신뢰성과 성능을 높이는 데 기여한다.
Write : 로그 스트림이 chunk에 저장되는 과정
- distributor는 스트림(로그)에 대한 데이터를 저장하기 위한 HTTP/1 요청을 받는다.
- 각 스트림은 해시 링을 사용하여 해시된다.
- distributor는 해시된 데이터를 각 스트림을 적절한 ingesters에 해당 복제본으로 보낸다.
- 각 ingesters는 스트림 데이터에 대해 chunk를 생성하거나 기존 chunk에 추가한다.
- distributor는 HTTP/1 연결을 통해 성공 코드로 응답한다.
Read Path: Query frontend, Querier
- Query Frontend와 Querier의 조합은 Grafana Loki에서 데이터 검색과 분석을 위한 효율적이고 강력한 읽기 경로를 제공한다.
- 이러한 구조는 대규모 데이터 세트에 대한 쿼리 처리 시간을 줄이고, 시스템의 전반적인 성능과 확장성을 향상시키는 데 중요한 역할을 한다.
- 특히, 캐싱과 쿼리 분할 같은 기능은 쿼리 응답 시간을 단축시키고 사용자 경험을 개선하는 데 크게 기여한다.
Query-Frontend(optional service)
- 실제 쿼리 실행에 필요한 Querier의 역할을 보조하며 읽기 경로를 가속화한다.
- Query frontend는 내부적으로 쿼리를 조정하고 큐에 보관한다.
- Query Frontend는 실제 쿼리를 실행하는 Querier를 보조하여 읽기 경로의 성능을 향상시키는 서비스이다.
- 이 서비스는 쿼리 실행을 더 효율적으로 만들기 위해 다음과 같은 주요 기능을 수행한다.
- 큐잉(Queueing) : 큰 쿼리로 인한 메모리 부족 문제를 방지하고, 공정한 스케줄링을 가능하게 한다. 이는 더 작은 쿼리의 병렬 실행을 통해 전체 소유 비용(TCO)을 줄이는 데 기여한다.
- 분할(Splitting) : 큰 쿼리를 여러 작은 쿼리로 분할하여 Querier의 메모리 부족 문제를 예방하고, 쿼리 결과를 더 빠르게 도출할 수 있도록 한다.
- 캐싱(Caching) : 쿼리 결과를 캐시하여 후속 쿼리에서 재사용합니다. 이는 쿼리 수행 시간을 단축시키고 전반적인 시스템 성능을 향상시키는 데 도움이 된다.
- Query Frontend는 상태를 유지하지 않는 서비스로, 일반적으로 두 개의 복제본으로 운영되며, 이는 가용성을 높이면서도 리소스 사용을 최적화한다.
Querier
- Ingester의 in-memory 데이터를 쿼리 후 장기 저장소에서 쿼리 로그를 가져와 Query-Frontend에게 데이터를 반환한다.
- Ingester에서 복제 데이터를 가져올 수 있기 때문에 내부적으로 중복을 제거한다.
- Querier는 LogQL 쿼리 언어를 사용하여 로그 데이터에 대한 쿼리를 처리한다.
- 인메모리 데이터 및 장기 저장소 쿼리 : 모든 Ingester에서 현재 메모리에 있는 데이터를 쿼리한 다음, 같은 쿼리를 장기 저장소에 대해서도 실행한다. 이는 실시간 데이터와 과거 데이터 모두에 대한 쿼리를 가능하게 한다.
- 중복 제거 : 복제로 인해 중복된 데이터를 수신할 수 있는데, Querier는 동일한 나노초 타임스탬프, 레이블 세트 및 로그 메시지를 가진 데이터를 중복 제거하여 최종 쿼리 결과의 정확성을 보장한다.
- Read Path에서 로그 스트림이 읽어지는 과정
- querier는 데이터에 대한 HTTP/1 요청을 받는다.
- querier는 인메모리 데이터에 대한 쿼리를 모든 ingesters에 전달한다.
- ingesters는 읽기 요청을 수신하고 쿼리와 일치하는 데이터가 있는 경우 반환한다.
- querier는 데이터를 반환한 ingesters가 없는 경우 백업 저장소에서 데이터를 느리게 로드하고 이에 대해 쿼리를 실행한다.
- querier는 수신된 모든 데이터를 반복하고 중복을 제거하여 HTTP/1 연결을 통해 최종 데이터 세트를 반환한다.
Read
- Read 요청 시 querier에서 해당 요청을 수신한다.
- querier는 ingester의 in-memory를 조회한다.
- ingester에 캐시 된 데이터가 있는 경우 querier에게 반환하고, 데이터가 없는 경우 백업 저장소(S3)에서 데이터를 조회한다.
- querier는 수신된 데이터가 중복 됐는지 확인 후 중복제거 진행하여 log를 제공한다.
Consistent Hash Rings
- 로그 라인의 샤딩, 고가용성 구현, 그리고 클러스터의 수평적 확장성(scaling)을 용이하게 하는 데 사용된다.
- 해시 링은 Loki의 다양한 컴포넌트 간의 효율적인 데이터 분배와 관리를 가능하게 한다.
- 각각의 노드는 Loki 시스템 내의 특정 컴포넌트 인스턴스를 대표하며, 키-값 저장소에는 해당 인스턴스의 통신 정보가 저장된다.
일관된 해시 링의 주요 특징 및 용도
- Distributor Ring : Distributor의 수를 계산하는 데 사용된다. 이는 로그 데이터가 어떻게 분산되어야 할지 결정하는 데 중요한 역할을 한다.
- Ingester Ring : 로그 라인을 어느 Ingester에 전달할지 결정하는 데 사용된다. 이는 데이터의 안정적인 저장과 검색을 위한 효율적인 데이터 분배 메커니즘을 제공한다.
- Query Scheduler Ring : 서비스 탐색에 사용된다. 쿼리 요청을 효율적으로 처리할 Querier를 결정하는 데 도움을 준다.
- Compactor Ring : 로그 데이터의 압축을 담당할 인스턴스를 식별하는 데 사용된다. 이는 저장 공간의 효율적 사용과 데이터 처리 성능 향상에 기여한다.
- Ruler Ring : 어떤 규칙 그룹을 평가할지 결정하는 데 사용된다. 이는 경고 및 메트릭 규칙을 효율적으로 관리하고 실행하는 데 중요하다.
- Index Gateway Ring(선택적) : 어떤 게이트웨이가 특정 테넌트의 인덱스를 담당할지 결정하는 데 사용된다. 이는 인덱스 데이터의 관리와 접근성을 향상시킨다.
중요성 및 이점
- 일관된 해시 링은 Grafana Loki의 분산 시스템에서 데이터를 균등하게 분배하고, 컴포넌트 간의 효율적인 통신을 가능하게 하는 핵심 메커니즘이다.
- 이는 시스템의 확장성, 고가용성, 그리고 관리 용이성을 보장한다.
- 또한, 클러스터의 동적인 스케일 업과 스케일 다운을 지원하여, 변화하는 워크로드에 빠르게 대응할 수 있게 한다.
- 일관된 해시 링을 통한 데이터의 효율적인 분배는 리소스 사용 최적화와 시스템의 전반적인 성능 향상을 이끌어내며, Grafana Loki를 대규모 로그 데이터를 처리하는 강력한 도구로 만든다.
Multi-tenancy
- Grafana Loki는 멀티테넌트 모드를 지원하여, 여러 사용자 또는 팀이 동일한 Loki 인스턴스를 공유할 수 있도록 한다.
- 이 모드에서는 메모리와 장기 저장소에 있는 모든 데이터가 HTTP 요청의 X-Scope-OrgID 헤더에서 가져온 테넌트 ID에 따라 파티셔닝된다.
- 멀티테넌트 모드가 아닐 경우, 테넌트 ID는 “fake”로 설정되며, 이는 모든 사용자의 데이터가 동일한 인덱스와 저장된 chunk에 표시됨을 의미한다.
- 이 기능은 데이터의 격리와 보안을 강화하며, 리소스 사용의 효율성을 높인다.
Storage
- TSDB
- Loki 버전 2.8부터는 TSDB(Time Series Database)를 사용하여 인덱스 저장소로서 NoSQL 저장소에 의존하지 않고도 Loki를 실행할 수 있게 되었다.
- 이전 버전까지는 Single Store(boltdb-shipper)가 이 역할을 담당했다.
- TSDB를 사용하면 모든 데이터(chunk와 인덱스)를 단일 오브젝트 스토리지 백엔드에 저장할 수 있으며, 이는 운영의 단순화, 비용 절감, 그리고 성능 향상을 가능하게 한다.
- TSDB 어댑터를 통한 인덱스 저장은 chunk 저장 방식과 유사하게 진행되어, Loki의 데이터 관리 방식을 더욱 통합하고 효율적으로 만든다.
- 이러한 요소들은 Grafana Loki를 효과적으로 운영하기 위한 핵심적인 부분이며, 대규모 로그 데이터 관리 시스템의 설계와 구현에 중요한 기여를 한다.
- Loki의 멀티테넌시 지원과 TSDB를 활용한 스토리지 관리는 사용자가 대규모 로그 데이터를 보다 유연하고 효율적으로 처리할 수 있게 돕는다.
Deployment modes
- Monolithic mode
- 하루에 최대 약 100GB의 읽기/쓰기 볼륨에 유용하다.
- Shared object store를 사용하여 라운드 로빈 방식 라우팅의 수평적 확장 구성 가능하다.
- Simple scalable deployment mode
- 하루에 수백 GB를 초과하거나 읽기 및 쓰기 문제를 분리하려는 경우에 유용하다.
- 이 배포 모드는 하루에 몇 TB 이상의 로그로 확장할 수 있다.
- Microservices mode
- components를 개별 마이크로서비스로 실행하면 마이크로서비스의 양을 늘려 확장할 수 있다.
- 마이크로서비스 모드는 규모가 매우 큰 Loki 클러스터 또는 확장 및 클러스터 작업을 더 많이 제어해야 하는 클러스터에 권장된다.
Compactor
- chunk 보관주기를 관리하고(retention), 테이블을 단일 인덱스 파일로 압축한다.
- Compactor를 통한 보존은 boltdb-shipper 또는 tsdb store에서만 지원된다.
- Loki 2.8부터는 TSDB Store 사용이 권장이다. 이전에 사용하던 boltdb-shipper보다 효율적이고 빠르며 확장성이 뛰어나다.
- Loki 2.8부터는 TSDB Store 사용이 권장이다. 이전에 사용하던 boltdb-shipper보다 효율적이고 빠르며 확장성이 뛰어나다.
Ruler
- 사용자가 정의한 경고 규칙 기반으로 경고를 발생시키는 등 로그 데이터에 대한 경고를 관리한다.
WAL(Write Ahead Log)
- Loki에서는 WAL(Write Ahead Log)이라는 걸 사용하는데, 아래와 같은 예기치 않은 장애 상황을 방지해 준다.
- 데이터(chunk)가 Ingesters로 들어오면, 먼저 이 데이터를 메모리 적재 및 WAL에 기록한다. WAL은 로컬 파일 시스템에 저장된다.
- 예기치 않은 장애로 프로세스가 갑자기 중단되거나 다운되면, 메모리에 있는 데이터가 손실된다.
- 장애가 복구되어 프로세스가 다시 시작되면 WAL에 저장된 데이터를 읽어와 메모리에 적재하여 장애 전의 상태로 복구된다.
Chunk Store
- Loki의 로그를 장기 저장하기 위한 저장소이다.
Index Gateway
- Querier, Ruler에게 Index 쿼리를 제공하기 위해 Object Storage 및 BoltDB 인덱스를 다운로드하고 동기화한다.
- 이렇게 하면 Grafana로부터 로그 검색 요청이 들어왔을 때 Querier나 Ruler가 불필요하게 일하지 않아도 된다.
Compactor와 Table Manager
- Grafana Loki의 로그 보존(Retention)은 Compactor 혹은 Table Manager에 의해 수행된다.
- 현재 Table Manager를 통한 Retention은 TTL을 통해 달성되며 boltdb-shipper, chunk/index store 모두 작동한다.
- Compactor를 통한 Retention은 boltdb-shipper 저장소에서만 지원된다.
- 만약 Compactor로 Retention을 적용한다면 Table Manager는 필요로 하지 않게 될 수 있다.
현재 Grafana Loki에서는 Compactor를 중점적으로 개발중인 것 같다.
- 다음은 Compactor 설정 예시이다.
1 2 3 4
compactor: shared_store: s3 retention_delete_delay: 2h retention_enabled: true
- Compactor의 Retention은 limits_config에 설정해주면 된다.
This post is licensed under CC BY 4.0 by the author.