Web 신입 면접 정리
Oracle 클러스터 인덱스와 넌 클러스터 인덱스의 차이
- 클러스터드 인덱스 : 실제 DB의 데이터 파일에 정렬되어 있는 상태로 디스크에 저장이 됨. (테이블당 한개)
- 넌클러스터드 인덱스 : 실제 DB의 데이터 파일에 정렬되지 않는 상태로 디스크에 저장이 됨.
GET 방식과 POST 방식?
- GET
- 클라이언트에서 서버로 데이터를 전달할 때, 주소 뒤에 “이름”과 “값”이 결합된 스트링 형태로 전달.
- 주소창에 쿼리 스트링이 그대로 보여지기 때문에 보안성이 떨어진다.
- 길이에 제한이 있다.(=전송 데이터의 한계가 있다.)
- Post 방식보다 상대적으로 전송 속도가 빠르다.
- POST
- 일정 크기 이상의 데이터를 보내야 할 때 사용한다.
- 서버로 보내기 전에 인코딩하고, 전송 후 서버에서는 다시 디코딩 작업을 한다.
- 주소창에 전송하는 데이터의 정보가 노출되지 않아 Get 방식에 비해 보안성이 높다.
- 속도가 Get 방식보다 느리다.
- 쿼리스트링(문자열) 데이터 뿐만 아니라, 라디오 버튼, 텍스트 박스 같은 객체들의 값도 전송가능.
- Get과 Post 차이점
- Get은 주로 웹 브라우저가 웹 서버에 데이터를 요청할 때 사용.
- Post는 웹 브라우저가 웹 서버에 데이터를 전달하기 위해 사용.
- Get을 사용하면 웹 브라우저에서 웹 서버로 전달되는 데이터가 인코딩되어 URL에 붙는다.
- Post 방식은 전달되는 데이터가 보이지 않는다.
- Get 방식은 전달되는 데이터가 255개의 문자를 초과하면 무넺가 발생할 수 있다.
- 웹서버에 많은 데이터를 전달하기 위해서는 Post 방식을 사용하는 것이 바람직하다.
Session과 Cookie
- Session과 Cookie 사용 이유
- 현재 우리가 인터넷에서 사용하고 있는 HTTP프로토콜은 연결 지향적인 성격을 버렸기 때문에 새로운 페이지를 요청할 때마다 새로운 접속이 이루어지며 이전 페이지와 현재 페이지 간의 관계가 지속되지 않는다. 이에 따라 HTTP프로토콜을 이용하게 되는 웹사이트에서는 웹페이지에 특정 방문자가 머무르고 있는 동안에 그 방문자의 상태를 지속시키기 위해 쿠키와 세션을 이용한다.
- Session
- 특정 웹사이트에서 사용자가 머무르는 기간 또는 한 명의 사용자의 한번의 방문을 의미한다.
- Session에 관련된 데이터는 Server에 저장된다.
- 웹 브라우저의 캐시에 저장되어 브라우저가 닫히거나 서버에서 삭제시 사라진다.
- Cookie에 비해 보안성이 좋다.
- Cookie
- 사용자 정보를 유지할 수 없다는 HTTP의 한계를 극복할 수 있는 방법.
- 인터넷 웹 사이트의 방문 기록을 남겨 사용자와 웹 사이트 사이를 매개해 주는 정보이다.
- Cookie는 인터넷 사용자가 특정 웹서버에 접속할 때, 생성되는 개인 아이디와 비밀번호, 방문한 사이트의 정보를 담은 임시 파일로써, Server가 아닌 Client에 텍스트 파일로 저장되어 다음에 해당 웹서버를 찾을 경우 웹서버에서는 그가 누구인지 어떤 정보를 주로 찾았는지 등을 파악할 때 사용된다.
- Cookie는 Client PC에 저장되는 정보기 때문에, 다른 사용자에 의해서 임의로 변경이 가능하다.(정보 유출 가능, Session보다 보안성이 낮은 이유)
- 보안성이 낮은 Cookie 대신 Session을 사용하면 되는데 안하는 이유?
- 모든 정보를 Session에 저장하면 Server의 메모리를 과도하게 사용하게 되어 Server에 무리가 감.
JDBC
- Java Data Base Connection의 약자로 JAVA 언어를 통해 데이터 베이스에 접근 할 수 있는 프로그래밍의 의미
Servlet vs JSP
- Servlet : 자바 언어로 웹 개발을 위해 만들어진 것으로, Container가 이해할 수 있게 구성된 순수 자바코드로만 이루어진 것.
- JSP : html 기반에 JAVA 코드를 블록화하여 삽입한 것으로 Servlet을 좀 더 쉽게 접근할 수 있도록 만들어 진 것.
Overloading(오버로딩)과 Overriding(오버라이딩)의 차이?
- Overloading(오버로딩)
- 메서드 명은 동일하지만, 매개 변수 타입과 개수를 다르게 해 선언하는 방식.
- 같은 이름의 메소드를 여러개 정의하는 것.
- 매개변수의 타입이 다르거나 개수가 달라야 한다.
- return type과 접근 제어자는 영향을 주지 않음.
- Overriding(오버라이딩)
- 상속한 자식에서 부모의 메서드를 재정의하는 방식(부모 클래스의 메소드를 자식 클래스에서 재정의)
MVC 패턴이란?
- Model : data 처리와 접근을 담당, 소프트웨어 응용과 그와 관련된 고급 클래스 내의 논리적 데이터 기반 구조를 표현, 이 목적 모형은 사용자 인터페이스에 관한 어떠한 정보도 가지고 있지 않다.
- View : Client에 보여지는 화면을 담당, 사용자 인터페이스 내의 구성요소들을 표현(사용자에게 보여지는 화면)
- Controller : Model과 View를 제어 하는 3가지 부분으로 나눔으로서, 데이터와 화면 간의 의존관계를 벗어날 수 있게하는 개발 기법.
- 사용자가 보는 페이지, 데이터 처리, 그리고 이 2가지를 중간에서 제어하는 컨트롤, 이 3가지로 구성되는 하나의 애플리케이션을 만들면 각각 맡은 바에만 집중을 할 수 있게 됨.
- 객체지향프로그래밍에서, MVC란 사용자 인터페이스를 성공적이며 효과적으로 데이터 모형에 관련 시키기 위한 방법론 또는 설계 방식 중 하나.
- MVC 패턴은 목적 코드의 재사용에 유용한 것은 물론, 사용자 인터페이스와 응용프로그램 개발에 소요되는 시간을 현저하게 줄여주는 형식이라고 많은 개발자들이 평가하고 있다.
싱글톤(SingleTone Pattern)
- 대표적으로 Calendar 객체나 dataSource 객체처럼 객체가 하나만 생성되어야 하는 경우 전체 코드에서 하나의 객체만 존재할 수 있도록 이미 생성된 객체가 있으면 그 객체를 사용하도록 하는 방식.
팩토리 패턴(Factory Pattern)
- 객체간 의존성을 줄이기 위해 객체의 생성과 데이터 주입만 담당하는 Factory Class를 정의하고 개발 코드 부분에서는 생성된 객체를 가져다 사용함으로서 의존성을 줄이는 방식.
옵저버 패턴(Observer Pattern)
- 기후 정보처럼 RSS 수신시 하나의 객체가 변하면 다른 객체에 객체가 변했다는 사항을 알려주어야 할 경우에 주로 사용.
Spring의 AOP(관점 지향 프로그래밍)란?
- AOP는 Aspect Oriented Programming 관점 지향 프로그래밍의 약자로, 기존의 OOP(객체 지향 프로그래밍)에서 기능별로 class를 분리했음에도 불구하고, 여전히 로그, 트랜잭션, 자원해제, 성능테스트 메서드처럼 공통적으로 반복되는 중복코드가 여전히 발생하는 단점을 해결하고자 나온 방식으로 이러한 공통 코드를 “횡단 관심사”라 표현하며 개발코드에서는 비지니스 로직에 집중하고 실행시에 비지니스 로직 앞, 뒤 등 원하는 지점에 해당 공통 관심사를 수행할 수 있게 함으로서 중복 코드를 줄일 수 있는 방식
- 공통의 관심사항을 적용해서 발생하는 의존관계의 복잡성과 코드 중복을 해소해 주는 프로그래밍 기법. OOP라 하면 관심사가 같은 기능과 데이터를 한데 모아서 객체 지향 설계 원칙에 따라 분리하고, 서로 낮은 결합도를 가진채 독립적이고 유연하게 확장할 수 있는 모듈로 캡슐화 하는 것을 일컫는다. 하지만 대부분의 프로젝트에서는 메소드의 호출 전후의 데이터 확인을 위한 로깅이나 예외처리, 데이터 검증과 관련된 코드가 클래스 전반에 걸쳐서 쓰여지고 있음. OOP 모듈화를 방해. 클래스 여기저기에 반복적으로 나타나서 핵심로직 코드의 가독성이나 확장성, 유지보수 등의 효율을 떨어뜨림. 이렇게 관련된 코드를 한데 모아 모듈화 하여 핵심 로직으로부터 분리하고 개발하는 방식을 AOP
- 장점 : 중복되는 코드 제거, Unit Testing 편의성, 유지보수성 향상
Spirng에서 IoC(제어의 역전)란?
- 프레임워크가 제어권을 가짐. 객체 생성도 컨테이너가 함. IoC 의존관계를 결정, 설정, 생명주기를 해결하기 위한 디자인 패턴
- IoC가 아닌 경우
1
String A = new String();
- IoC인 경우
1 2
@Autowired UserService userService;
- 객체 생성 생명 주기 관리. 의존성 관리. POJO의 생성, 초기화, 서비스, 소멸에 대한 권한을 가짐.
IoC 분류
DL(의존성 검색(특정 컨테이너에 종속되는 API 사용)) : 저장소에 저장되어 있는 Bean에 접근하기 위해 컨테이너가 제공하는 API를 이용하여 Bean을 조회하는 것. 컨테이너가 제공하는 API를 사용하기 때문에 컨테이너에 종속성이 늘어남.
- DI : 각 클래스간의 의존관계를 Bean설정 정보를 바탕으로 컨테이너가 자동으로 연결시켜주는 것. ** SetterInjection(셋터를 통해 주입) ** Constructor(생성자를 통해 주입) ** Method(자바 메서드를 통해 주입)
- 의존관계 Bean설정(사용자가 설정해줌), 어노테이션 등등이 있다. 컨테이너가 정보들을 읽고 자동으로 설정.
1 2
@Autowired // 의존관계 설정 UserService userService;
- 컨테이너가 흐름의 주체가 된다.(사용자가 설정해준 것을 컨테이너가 연결)
- 장점 : 코드가 단순, 컴포넌트 간의 결합도 제거
- Spring DI 컨테이너가 관리하는 객체를 Bean, 이 Bean들을 관리한다는 의미로 컨테이너를 Bean Factory.
- Spring API에서 BeanFactory 인터페이스 제공.
- BeanFactory에 여러가지 컨테이너 기능을 추가하여 애플리케이션 컨텍스트라고 부름.
- BeanFactory : Bean을 등록, 생성, 조회, 반환 관리한다. 이를 확장한 것이 Application Context.
- Application Context(DI 컨테이너 역할) : Spring의 각종 부가 서비스 추가 제공.
POJO(특정 규약에 종속되지 않는 자바 객체?)
- 특정 규약에 종속되지 않는다.
- 특정 환경에 종속되지 않는다.
객체 지향 원리에 충실해야 한다.
- 사용 이유
- 코드 간결함.
- 자동화 테스트에 유리.
- 객체지향적 설계의 자유로운 사용.
Spring에서 DI(의존성 주입)란?
- DI는 Dependency Injection(의존성 주입)의 약자로, 객체들 간의 의존성을 줄이기 위해 사용되는 Spring의 IoC 컨테이너의 구체적인 구현 방식, DI는 기존처럼 개발코드 부분에서 객체를 생성하는 것이 아니라, 팩토리 패턴처럼 객체의 생성과, 데이터를 주입만 담당하는 Factory에 해당 하는 별도의 공간에서 객체를 생성하고 데이터간의 의존성을 주입해 개발코드에서는 이를 가져다 씀으로서 의존성을 줄이는 방식. 이 때, Factory 패턴의 Factory Class의 역할을 Spring의 환경설정 파일이 담당.
- 객체 간의 의존관계를 객체 자신이 아닌 외부 조립기가 수행해준다는 개념. DI패턴을 적용할 경우 클래스는 의존하는 객체를 전달받기 위한 설정 메소드다. 생성자를 제공할 뿐 직접 의존하는 클래스를 찾지 않음. 의존하는 객체를 조립기가 삽입해주기 때문에 이 방식을 DI패턴이라고 함. DI패턴 사용시 단위테스트가 가능. 단위테스트는 코드의 품질을 향상시키고 개발속도 증가 시킴. 의존적인 객체를 직접 생성하거나 제어하는 것이 아니라, 특성 객체에 필요한 객체를 외부에서 결정해서 연결시키는 것.
DAO
- Database의 data에 접근하기 위한 객체
DTO
- 로직을 가지지 않은 순수 데이터 객체(getter, setter)
Spirng MVC 처리 순서
- 클라이언트가 서버에 어떤 요청을 한다면 스프링에서 제공하는 DispatcherServlet이라는 클래스가 요청을 가로챈다.
- 요청을 가로챈 DispatcherServlet은 HaddlerMapping에게 어떤 컨트롤러에게 요청을 위임하면 좋을지 물어본다.
- 요청에 매핑된 컨트롤러가 있다면
@RequestMapping을 통하여 요청을 처리할 메서드에 도달한다. - 컨트롤러에서는 해당 요청을 처리할 Service를 주입(DI)를 받아 비지니스 로직을 Service에게 위임한다.
- Service에서는 요청에 필요한 작업 대부분(코딩)을 담당, DB처리는 DAO를 주입 받아 위임한다.
- DAO는 mybatis 설정을 이용해 SQL쿼리를 날려 DB의 정보를 받아 서비스에게 다시 돌려준다.이 때 보통 VO(DTO)를 컨트롤러에서부터 내려받아 쿼리의 결과를 VO에 담는다.(mybatis의 resulttype)
- 모든 로직을 끝낸 서비스가 결과를 컨트롤러에게 넘긴다.
- 결과를 받은 컨트롤러는 Model 객체에 결과물인 어떤 view(jsp) 파일을 보내줄 것인지 등의 정보를 담아 DispatcherServlet에게 보낸다.
- DispatcherServlet은 ViewResolver에게 받은 뷰의 대한 정보를 넘긴다.
- ViewResolver는 해당 jsp를 찾아서(응답할 view를 찾음) DispatcherServlet에게 알려준다.(servlet-context.xml에서 suffix, preffix를 통해 /WEB-INF/views/index.jsp 이렇게 만들어주는 것도 ViewResolver)
- DispatcherServlet은 응답할 view에게 Render를 지시하고 view는 응답 로직을 처리한다.
- 결과적으로 DispatcherServlet이 클라이언트에게 렌더링된 view를 응답한다.
추상메서드? 추상클래스? Interface(인터페이스)?
- 추상메서드 : 메서드의 정의부만 있고 구현부는 있지 않은 메서드
- 추상클래스 : 추상메서드를 적어도 하나 이상 가지고 있는 클래스로 자식클래스에서 오버라이딩(재정의)가 필요한 추상메서드를 가지고 있기 때문에 객체화 할 수 없다.
- Interface(인터페이스)
- 일종의 추상 클래스.
- 오직 추상 메서드와 상수만을 멤버로 갖는다.
- Implements 키워드를 사용.
- 상속의 관계가 없는 클래스간 서로 공통되는 로직을 구현하여 쓸 수 있도록 한다.
- Extends는 하나의 클래스만 상속 가능하나 Interface는 다중 상속이 가능하다.
- Abstract
- 추상메서드를 하나 이상 가진 클래스.
- 자신의 생성자로 객체 생성 불가능.
- 하위 클래스를 참조하여 상위 클래스의 객체를 생성.
- 하위 클래스를 제어하기 위해 사용.
- Interface vs Abstract
- 공통점
- new 연산자로 인스턴스 생성 불가능.
- 프로토타입만 있는 메서드를 갖는다.
- 사용하기 위해서는 하위클래스에서 확장/구현 해야 한다.
- 차이점
- 사용하는 키워드가 다르다.
- Abstract는 일반 메서드를 사용할 수 있지만, Interface는 메서드 선언만 가능하다.
- 공통점
Call by Reference, Call by Value
- Call by Reference : 매개 변수의 원래 주소에 값을 저장하는 방식, 클래스 객체를 인수로 전달한 경우
- Call by Value : 인수로 기본 데이터형을 사용, 주어진 값을 복사하여 처리하는 방식, 메서드 내의 처리 결과는 메서드 밖의 변수에 영향을 미치지 않는다.
Static
- 클래스가 로딩될 때, 메모리 공간을 할다하는데 처음 설정된 메모리 공간이 변하지 않음을 의미.
- 객체를 아무리 많이 만들어도 해당 변수는 하나만 존재(객체와 무관한 키워드)
캐시(Cache)와 세션(Session)의 공통점과 차이점은?
- 공통점 : 둘 다 사용자의 데이터를 저장
- 캐시 : 캐시는 Client 컴퓨터에 저장했다 서버 요청시 네트워크를 타고 서버로 전달되기 때문에 보안에 취약하다.
- 세션 : 세션은 서버에 저장되고 브라우저 단위로 관리된다. 캐시에 비해 보안성이 좋다.
프로세스(Process)와 쓰레드(Thread)의 차이점?
- 프로세스(Process) : OS가 메모리 등의 자원을 할당해준 실행중인 프로그램을 가리킨다. 이 때, 각각의 프로세스는 서로 메모리 공간을 독자적으로 갖기 때문에 서로 메모리 공간을 공유하지 못한다. 따라서 공유하기 위해서는 IPC(InterProcess Communication)과 같은 방식이 필요.
- 쓰레드(Thread) : 쓰레드는 프로세스 내에서 프로세스의 자원을 가지고 실제로 일하는 “일꾼”과 같으며 각 쓰레드는 독자적인 Stack 메모리를 갖고 그 외의 자원(메모리)는 프로세스 내에서 공유하기 된다. 프로세스 내에서 동시에 실행되는 독립적인 실행 단위를 말함. 장점으로는 자원을 많이 사용하지 않고 구현이 쉬우며 범용성이 높다.
- 쓰레드(Thread) 장점
- 빠른 프로세스 생성
- 적은 메모리 사용
- 쉬운 정보 공유
- 쓰레드(Thread) 단점
- 교착상태에 빠질 수 있다.(교착상태 : 다중프로그래밍 체제에서 하나 또는 그 이상의 프로세스가 수행할 수 없는 어떤 특정시간을 기다리고 있는 상태)
- 데드락 : 프로세스가 자원을 얻지 못해 다음 처리를 못하는 상태로, ‘교착 상태’라고도 하며 시스템적으로 한정된 자원을 여러 곳에서 사용하려고 할 때 발생.
- 발생 조건
- 상호 배제(Mutual Exclusion) : 자원은 한 번에 한 프로세스만이 사용할 수 있어야 한다.
- 점유 대기(Hold and Wait) : 최소한 하나의 자원을 점유하고 있으면서 다른 프로세스에 할당되어 사용하고 있는 자원을 추가로 점유하기 위해 대기하는 프로세스가 있어야 한다.
- 비선점(No preemption) : 다른 프로세스에 할당된 자원은 사용이 끝날 때까지 강제로 빼앗을 수 없어야 한다.
- 순환 대기(Circular Wait) : 프로세스의 집합 {P0, P1, , … Pn}에서 P0는 P1이 점유한 자원을 대기하고 P1은 P2가 점유한 자원을 대기하고 P2…Pn-1은 Pn이 점유한 자원을 대기하며 Pn은 P0가 점유한 자원을 요구해야 한다.
- 발생 조건
- 쓰레드(Thread) 장점
- 프로세스(Process)와 쓰레드(Thread) 차이
- 여러 분야에서 ‘과정’ 또는 ‘처리’라는 뜻으로 사용되는 용어로 컴퓨터 분야에서는 ‘실행중인 프로그램’이라는 뜻으로 쓰인다. 이 프로세스 내에서 실행되는 각각의 일을 쓰레드라고 한다. 프로세스 내에서 실행되는 세부 작업 단위로 여러 개의 쓰레드가 하나의 프로세스를 이루게 되는 것이다.
자바 스레드(Java Thread) 란?
- 일반 스레드와 거의 차이가 없으며, JVM가 운영체제의 역할을 한다.
- 자바에는 프로세스가 존재하지 않고 스레드만 존재하며, 자바 스레드는 JVM에 의해 스케줄되는 실행 단위 코드 블록이다.
- 자바에서 스레드 스케줄링은 전적으로 JVM에 의해 이루어진다.
- 아래와 같은 스레드와 관련된 많은 정보들도 JVM이 관리한다.
- 스레드가 몇 개 존재하는지
- 스레드로 실행되는 프로그램 코드의 메모리 위치는 어디인지
- 스레드의 상태는 무엇인지
- 스레드 우선순위는 얼마인지
- 즉, 개발자는 자바 스레드로 작동할 스레드 코드를 작성하고, 스레드 코드가 생명을 가지고 실행을 시작하도록 JVM에 요청하는 일 뿐이다.
멀티 프로세스와 멀티 스레드의 차이
- 멀티 프로세스
- 멀티 프로세싱이란
- 하나의 응용프로그램을 여러 개의 프로세스로 구성하여 각 프로세스가 하나의 작업(태스크)을 처리하도록 하는 것이다.
- 장점
- 여러 개의 자식 프로세스 중 하나에 문제가 발생하면 그 자식 프로세스만 죽는 것 이상으로 다른 영향이 확산되지 않는다.
- 단점
- Context Switching에서의 오버헤드
- Context Switching 과정에서 캐쉬 메모리 초기화 등 무거운 작업이 진행되고 많은 시간이 소모되는 등의 오버헤드가 발생하게 된다.
- 프로세스는 각각의 독립된 메모리 영역을 할당받았기 때문에 프로세스 사이에서 공유하는 메모리가 없어, Context Switching가 발생하면 캐쉬에 있는 모든 데이터를 모두 리셋하고 다시 캐쉬 정보를 불러와야 한다.
- 프로세스 사이의 어렵고 복잡한 통신 기법(IPC)
- 프로세스는 각각의 독립된 메모리 영역을 할당받았기 때문에 하나의 프로그램에 속하는 프로세스들 사이의 변수를 공유할 수 없다.
- Context Switching에서의 오버헤드
- 멀티 프로세싱이란
- 참고 Context Switching란?
- CPU에서 여러 프로세스를 돌아가면서 작업을 처리하는 데 이 과정을 Context Switching라 한다.
- 구체적으로, 동작 중인 프로세스가 대기를 하면서 해당 프로세스의 상태(Context)를 보관하고, 대기하고 있던 다음 순서의 프로세스가 동작하면서 이전에 보관했던 프로세스의 상태를 복구하는 작업을 말한다.
- 멀티 스레드
- 멀티 스레딩이란
- 하나의 응용프로그램을 여러 개의 스레드로 구성하고 각 스레드로 하여금 하나의 작업을 처리하도록 하는 것이다.
- 윈도우, 리눅스 등 많은 운영체제들이 멀티 프로세싱을 지원하고 있지만 멀티 스레딩을 기본으로 하고 있다.
- 웹 서버는 대표적인 멀티 스레드 응용 프로그램이다.
- 장점
- 시스템 자원 소모 감소 (자원의 효율성 증대)
- 프로세스를 생성하여 자원을 할당하는 시스템 콜이 줄어들어 자원을 효율적으로 관리할 수 있다.
- 시스템 처리량 증가 (처리 비용 감소)
- 스레드 간 데이터를 주고 받는 것이 간단해지고 시스템 자원 소모가 줄어들게 된다.
- 스레드 사이의 작업량이 작아 Context Switching이 빠르다.
- 간단한 통신 방법으로 인한 프로그램 응답 시간 단축
- 스레드는 프로세스 내의 Stack 영역을 제외한 모든 메모리를 공유하기 때문에 통신의 부담이 적다.
- 시스템 자원 소모 감소 (자원의 효율성 증대)
- 단점
- 주의 깊은 설계가 필요하다.
- 디버깅이 까다롭다.
- 단일 프로세스 시스템의 경우 효과를 기대하기 어렵다.
- 다른 프로세스에서 스레드를 제어할 수 없다. (즉, 프로세스 밖에서 스레드 각각을 제어할 수 없다.)
- 멀티 스레드의 경우 자원 공유의 문제가 발생한다. (동기화 문제)
- 하나의 스레드에 문제가 발생하면 전체 프로세스가 영향을 받는다.
- 멀티 프로세스 대신 멀티 스레드를 사용하는 이유?
- 멀티 프로세스 대신 멀티 스레드를 사용하는 것의 의미?
- 쉽게 설명하면, 프로그램을 여러 개 키는 것보다 하나의 프로그램 안에서 여러 작업을 해결하는 것이다.
- 멀티 스레딩이란
멀티 프로세스 대신 멀티 스레드를 사용하는 이유?
- 멀티 프로세스 대신 멀티 스레드를 사용하는 것의 의미?
- 쉽게 설명하면, 프로그램을 여러 개 키는 것보다 하나의 프로그램 안에서 여러 작업을 해결하는 것이다.
- 여러 프로세스(멀티 프로세스)로 할 수 있는 작업들을 하나의 프로세스에서 여러 스레드로 나눠가면서 하는 이유?
- 자원의 효율성 증대
- 멀티 프로세스로 실행되는 작업을 멀티 스레드로 실행할 경우, 프로세스를 생성하여 자원을 할당하는 시스템 콜이 줄어들어 자원을 효율적으로 관리할 수 있다.
- –> 프로세스 간의 Context Switching시 단순히 CPU 레지스터 교체 뿐만 아니라 RAM과 CPU 사이의 캐쉬 메모리에 대한 데이터까지 초기화되므로 오버헤드가 크기 때문
- 스레드는 프로세스 내의 메모리를 공유하기 때문에 독립적인 프로세스와 달리 스레드 간 데이터를 주고 받는 것이 간단해지고 시스템 자원 소모가 줄어들게 된다.
- 처리 비용 감소 및 응답 시간 단축
- 또한 프로세스 간의 통신(IPC)보다 스레드 간의 통신의 비용이 적으므로 작업들 간의 통신의 부담이 줄어든다.
- –> 스레드는 Stack 영역을 제외한 모든 메모리를 공유하기 때문
- 프로세스 간의 전환 속도보다 스레드 간의 전환 속도가 빠르다.
- –> Context Switching시 스레드는 Stack 영역만 처리하기 때문
- 자원의 효율성 증대
메모리 영역
- 메서드 영역 : static 변수, 전역변수, 코드에서 사용되는 Class 정보 등이 올라간다. 코드에서 사용되는 Class들을 로더로 읽고 클래스별로 런타임 필드데이터, 메서드 데이터 등을 분류해 저장.
- 스택(Stack) : 지역변수, 함수(메서드) 등이 할당되는 LIFO(Last In First Out) 방식의 메모리
- 힙(Heap) : new 연산자를 통한 동적할당된 객체들이 저장되며, 가비지 컬렉션에 의해 메모리가 관리되어 진다.
메모리 구조
- 코드(Code) 영역 : 실행할 프로그램의 코드가 저장되는 영역으로 텍스트(Code) 영역이라고도 부름, CPU는 코드 영역에 저장된 명령어를 하나씩 가져가서 처리하게 됨.
- 데이터(Data) 영역 : 전역 변수, 정적(Static) 변수가 저장되는 영역, 데이터 영역은 프로그램의 시작과 함께 할당되며, 프로그램이 종료되면 소멸함.
- 힙 영역 : 사용자의 의해 메모리 공간이 동적으로 할당되고 해제됨, 메모리의 낮은 주소에서 높은 주소의 방향으로 할당됨.
- 스택(Stack) 영역 : 지역 변수, 매개 변수가 저장되는 영역, 스택 영역은 함수의 호출과 함께 할당되며, 함수의 호출이 완료되면 소멸함.
접근제한자(public > protected > default > private)
- public : 접근 제한이 없다.(같은 프로젝트 내에 어디서든 사용가능)
- protected : 같은 패키지 내. 다른 패키지에서 상속받아 자식클래스에서 접근 가능.
- default : 같은 패키지 내에서만 접근 가능.
- private : 같은 클래스 내에서만 접근 가능.
RestFul API
- 해당 UR만 보더라도 바로 어떤 작업을 하는지를 알 수 있도록 하나의 데이터는 하나의 URL을 갖도록 작업하는 방식.
- 규칙
- 자원
- 메소드만으로 표현
- 동사 말고 명사만
- 확장자는 표시하지 않음
- Get, Put, Post, Delete
- 웹에 존재하는 모든 자원(이미지, 동영상, DB자원)에 고유한 URI를 부여해 활용. 자원을 정의하고 자원에 대한 주소를 지정하는 방법론을 의미. 다양한 Device를 대응하기 위해
IaaS
- 기업(아마존이나 마소)이 준비해놓은 환경에서 사용자가 선택.
- AWS, EC2, Azure.
- 고객은 OS와 어플리케이션을 직접 관리.
- 관리 측면에서 개발자와 인프라 관리자의 역할 분담.
- 장점 : 고객은 가상 서버 하위의 레벨에 대해서는 고려할 필요가 없다는 점.
PaaS
- 운영팀이 인프라를 모니터링할 필요가 없음.
- 사용자는 OS, Server 하드웨어, 네트워크 등등을 고려할 필요가 없음.
- 사용자는 어플리케이션 자체에만 집중할 수 있음.
- 우리는 소스코드만 적어서 빌드하는 것이고, 컴파일은 클라우드에서 하며 결과만 가져오는 것.
- 장점 : PaaS의 경우 이미 설치된 미들웨어 위에 코드만 돌리면 되기 때문에 아무래도 관리가 매우 편함.
- 단점 : 기본적으로 어플리케이션과 플랫폼이 함께 제공됨. 어플리케이션이 플랫폼에 종속되어 개발되기 때문에 다른 플랫폼으로의 이동이 어려울 수도 있음.
- ex) Heroku, Google App Engine, IBM Bluemix
SaaS
- 모든 것을 기업(클라우드)에서 제공함으로 사용자는 별도의 설치나 부담이 필요없이 SW을 사용.
- 장점
- Public Cloud에 있는 SW를 웹브라우저로 불러와 언제 어디서나 사용.
- 사용자는 웹만 접속하면 되기 때문에 사용하기 매우 쉽고, 최신 SW업데이트를 빠르게 제공받을 수 있음.
- 단점
- SaaS의 특성상 반드시 인터넷에 접속할 수 있어야만 사용, 외부의 데이터 노출에 대한 위험.
- ex) 웹메일, 구글 클라우드, 드롭박스 등
Serverless 아키텍처
BaaS : Firebase
- 필요한 다양한 기능들(데이터베이스, SNS연동, 파일시스템 등)을 쉽고 빠르게 구현할 수 있게 해주고, 서버도 알아서 확장.
- 백엔드 로직들이 클라이언트 쪽에서 구현해야 함.
- 복잡한 쿼리가 불가능함.
FaaS : AWS Lambda
- 프로젝트를 여러개의 함수로 쪼개서, 매우 거대하고 분산된 컴퓨팅 자원에 우리가 준비해둔 함수를 등록하고, 이 함수들이 실행되는 횟수 만큼 비용을 내는 방식.
- 어플리케이션이 아닌 함수를 배포하며, 계속 실행되고 있는 것이 아닌, 특정 이벤트가 발생했을 때 실행되며, 실행이 되었다가 작업을 마치며 종료.
Serverless의 장점
- 서버 스케일링이 필요없다.
- 요즘 서버를 직접 운영하는 경우는 잘 없고 대부분 클라우드 서비스를 이용한다. 서버가 죽는 대부분의 경우는 서버가 감당가 능한 통신 대역폭, 메모리 용량, 컴퓨팅 능력을 넘어서는 요청이 들어오는 경우이다. 대부분의 경우는 그렇게 요청이 많이 들어오는 것에 대해서 어느 정도 알 수 있으므로, 미리 서버를 많이 늘려놓으면 된다. 그리고 요즘은 클라우드 서비스 상에 컨테이너를 이용해서 스케일링해주는 서비스 를 대부분 제공해주므로, 오토 스케일링을 설정해 놓으면 해결된다. 하지만 컨테이너에 서버 이미지를 복사해서 가동하는데 대략 15분의 시간이 걸린다고 가정했을 때, 15분동안 기존에 실행하고 있던 서버들 이 죽지않고 요청들을 잘 처리해 준다면 문제가 되지 않지만 그러지 못할 경우에는 바로 장애가 발생하는거다. 심지어 ELB에 같이 물렸을 때에 AWS EC2가 이미 전멸해 있고 트래픽은 계속 몰리는 상태에서 AutoScaling으로 삐용하고 올라와도 트래픽 몰매맞고 또 뻗어버린다.
- 비용
- 싸다. 다른 말이 더 필요한가 ? AWS EC2 서버로 운영하는것 보다 Lambda + API Gateway를 이용해서 API를 서비스 해보니 훨씬 더 싸다. EC2의 경우에는 운영중인 서버수 x 서버 인스턴스의 비용 x 서버가 운영중인 기간 (1시간 단위)로 과금이 이루어 진다. Lambda의 경우는 코드 가 수행된 시간을 100ms 단위로 올림하여 과금한다. API Gateway의 경우 100만 요청 당 3.5 USD가 과금된다. 이렇게 봐서는 과연 더 싼지 바로 판단이 안되겠지만, 실제로 운영해보니 훨씬 더 싸다. 비교도 안되게 싸다. 일단 이 두가지가 직접 겪었던 큰 이유다. 이것 말고도 여러가지 발표자료들을 찾아보면 다른 장점들이 많다. 하지만 그건 옵션 사항인듯 하다.
- 비용: 특정 작업을 하기 위하여 서버를 준비하고 하루종일 켜놓는것이 아니라, 필요할때만 함수가 호출되어 처리되며 함수가 호출된 만큼만 비용이 드므로, 비용이 많이 절약됩니다.
- 인프라 관리: 네트워크, 장비 이런것들에 대한 구성 작업을 신경 쓸 필요 없습니다.
- 인프라 보안: 리눅스 업데이트, 최근 발생한 Intel Meltdown 취약점 보안패치, 이런것들 또한 신경 쓸 필요 없습니다.
- 확장성: FaaS 는 확장성 면에서 매우 뛰어납니다. 일반적으로, FaaS 를 사용하지 않는다면, 다양한 트래픽에 유연한 대응을 하기 위하여 우리는 AWS 의 Auto Scaling 같은 기술을 사용합니다. 이를 통하여 CPU 사용량, 네트워크 처리량에 따라 서버의 갯수를 늘리는 방식으로 처리를 분산시키는데요, FaaS 를 사용하게 되면 이렇게 특정 조건에 따라 자동으로 확장되는 것이 아닙니다. 그냥, 확장됩니다. 함수가 1초에 1개가 호출되면 1개가 호출되는것이고, 100,000,00 개가 호출되면 100,000,00 개가 호출되는것입니다. 그리고 호출된 횟수 만큼 돈을 내는거죠.
Serverless의 단점
- 제한: 모든 코드를 함수로 쪼개서 작업하다보니, 함수에서 사용 할 수 있는 자원에 제한이 있습니다. 하나의 함수가 한번 호출 될 때, AWS 에서는 최대 1500MB 의 메모리까지 사용 가능하며, 처리시간은 최대 300 초 까지 사용 가능합니다. 때문에, 웹소켓 같이 계속 켜놔야 하는것은 사용하지 못합니다. 그 대신에, AWS IoT, Pusher 등의 서비스를 사용하면 됩니다.
- FaaS 제공사에 강한 의존: AWS, Azure, Google 등의 FaaS 제공사에 강한 의존을 하게 됩니다. 즉, 갑자기 이 회사들이 망해버리면…? 정말 골치 아프겠죠. 물론 가능성은 매우 희박합니다. 로컬 데이터 사용 불가능: 함수들은 무상태적(stateless)입니다. 때문에, 데이터를 로컬 스토리지에서 읽고 쓸 수 없습니다. 그 대신에, AWS 라면 S3, Azure 라면 Storage 를 이용 할 수 있습니다.
- 비교적 신기술: FaaS 는 비교적 새로운 기술 입니다. 물론 AWS 에서 Lambda 는 2014년에 등장하긴 했지만요, 주관적으로 보기엔, 2016년쯤 사용률이 올라가기 시작했으며, 이제 기업에서 사용한 사례들도 여럿 등장하며 자리를 잡아가고 있습니다. 2018년, 아직까지는, 해외에서는 관련 자료들을 볼 수 있는 반면, 국내에서는 관련 자료를 찾아보기가 힘듭니다. 아마 2020년 쯤에는 조금 더 국내에서도 관련 자료를 많이 찾아 볼 수 있을 것이라 예상합니다.
폭포수?
- 한 번 떨어지면 거슬로 올라갈 수 없는 폭포수와 같이 소프트웨어 개발도 각 단계를 확실히 매듭짓고, 다음 단계로 넘어간다는 의미.
- 각 단계가 명확하여 관리가 쉬우나, 폭포수 모델을 따르기 위해서는 완전히 순차적으로 한 단계, 한 단계를 진행해야 함.
- 즉, 폭포수 모델은 전 단계가 수행되어 완료되기 전에는 다음 단계로 진행할 수 없도록 제한하는 것이 가장 큰 특징.
- 그러므로 요구 분석에 상당한 시간이 소요되며, 일단 분석이 끝나면 수정이 어렵다는 단점. 또 개발 단계마다 피드백이 발생하므로 순차적인 흐름을 따라가기 어려우며, 규모가 크고 복잡한 시스템에는 적합하지 않다.
애자일?
- 폭포수 모델을 보완하여 나온 것이 애자일 모델.
- 일정한 주기를 가지고 끊임 없이 프로토타입을 만들어내며 그 때 그 때 필요한 요구를 더하고 수정하여 하나의 커다란 소프트웨어를 개발해 나가는 방법.
스크럼?
- 작은 단위의 개발 업무를 단기간 내에 전력 질주하여 개발한다는 뜻. 애자일 개발 방법론 중 하나.
- 장점
- 반복주기(스프린트)마다 생산되는 실행 가능한 제품을 통해 사용자와 충분히 의견을 나눌 수 있다.
- 일일회의를 함으로써 팀원들 간에 신속한 협조와 조율이 가능하다.
- 일일회의 시 직접 자신의 일정을 발표함으로써 업무에 집중할 수 있는 환경이 조성된다.
- 다른 개발 방법론들에 비해 단순하고 실천지향적이다.
- 스크럼 마스터는 개발 팀원들이 목표달성에 집중할 수 있도록 팀의 문제를 해결한다.
- 프로젝트의 진행 현황을 볼 수 있어, 목표에 맞게 변화를 시도할 수 있으며, 신속하게 목표와 결과 추정이 가능하다.
- 단점
- 추가 작업 시간 필요 : 반복주기(스프린트)가 끝날 때 마다 실행가능하거나 테스트할 수 있는 제품을 만들어야 한다. 이 작업이 많아지면, 그만큼 시간이 더 필요하다.
- 투입 공수 불측정에 따른 효율성 평가 불가 : 투입 공수를 측정하지 않기 때문에 얼마나 효율적으로 수행되었는지는 알기 어렵다.
- 프로세스 품질 평가 불가 : 스크럼은 프로젝트 관리에 무게 중심을 많이 둔 방법. 따라서 스프린트 수행 후 검토 회의를 하지만 프로세스 품질을 평가하지 않기 때문에 품질 관련 활동이 미약하고 따라서 품질의 정도를 알 수 없다.
- 장점
데브옵스(DevOps)의 장단점
- 개발(Development)과 운영(Operations)의 합성어로 시스템 개발과 운영을 병행 및 협업하는 방식 개발자는 개발이 완료된 시스템을 운영팀에게 이관하고 운영팀은 개발된 시스템을 배포/ 관리 운영을 한다는 것을 말함. 서로 주어진 업무로 전문적인 자기 분야에 집중할 수 있어 높은 퀄리티와 책임감으로 위험 감소가 보장된다는 장점이 있지만, 협업을 위해서 개발자는 운영자를, 운영자는 개발자를 생각하는 오픈 마인드를 가지고 커뮤니케이션이 되어야 함.
- 시스템 발생 장애 시스템 운영 시 장애가 발생되는 것은 고질적인 문제라고 볼 수 있는데요. 대부분 이런 상황에 부딪힐 때 근본적인 원인을 민첩하게 해결하지 못하고 서로 책임 전가하느라 클라이언트 요구 사항의 반영이 늦어진다는 것
- 추가되는 이슈와 요청 사항 거절 운영팀은 서비스 운영에도 업무가 포함되어 있기 때문에 다양한 VOC(고객의 소리-Voice Of Customer)의 이슈 및 개선 사항을 취합하게 되는데요. 이 부분을 개발팀에게 넘겼을 때 운영의 업무를 이해하지 못하고 추가적인 업무로 인식하여 쉽게 받아들이지 못한다는 것
- 노옵스(NoOps)란 단어 그대로 운영자가 없다는 뜻.
- 개발자는 발전된 인터넷으로 지식, 각종 오픈 소스, 클라우드를 통해 시스템 운영자 없이도 네트워크 및 서버 등 다양한 설정을 습득하여 직접 처리할 수 있는 환경이 되면서 직접 개발한 시스템의 방향 및 범위까지 파악된 상태로 장애 발생 또는 요구사항의 대응과 처리 속도가 빠르고 조금 더 효율적이라는 것.
마이크로 아키텍처와 모놀리스 아키텍처 장단점과 설명
- 모노리틱 아키텍쳐(Monolithic Architecture)
- 마이크로 서비스 아키텍쳐를 이해하려면 먼저 모노리틱 아키텍쳐 스타일에 대해서 이해해야 한다. 모노리틱 아키텍쳐 스타일은 기존의 전통적인 웹 시스템 개발 스타일로, 하나의 애플리케이션 내에 모든 로직들이 모두 들어 가 있는 “통짜 구조” 이다.
- 예를 들어, 온라인 쇼핑몰 애플리케이션이 있을때, 톰캣 서버에서 도는 WAR 파일(웹 애플리케이션 패키징 파일)내에, 사용자 관리,상품,주문 관리 모든 컴포넌트들이 들어 있고 이를 처리하는 UX 로직까지 하나로 포장되서 들어가 있는 구조이다. 각 컴포넌트들은 상호 호출을 함수를 이용한 call-by-reference 구조를 취한다. 전체 애플리케이션을 하나로 처리하기 때문에, 개발툴 등에서 하나의 애플리케이션만 개발하면 되고, 배포 역시 간편하며 테스트도 하나의 애플리케이션만 수행하면 되기 때문에 편리하다.
- 문제점
- 그러나 이러한 모노리틱 아키텍쳐 시스템은 대형 시스템 개발시 몇가지 문제점을 갖는다. 모노리틱 구조의 경우 작은 크기의 애플리케이션에서는 용이 하지만, 규모가 큰 애플리케이션에서는 불리한 점이 많다. 크기가 크기 때문에, 빌드 및 배포 시간, 서버의 기동 시간이 오래 걸리며 (서버 기동에만 2시간까지 걸리는 사례도 경험해봤음) 프로젝트를 진행하는 관점에서도, 한두사람의 실수는 전체 시스템의 빌드 실패를 유발하기 때문에, 프로젝트가 커질 수 록, 여러 사람들이 협업 개발하기가 쉽지 않다. 또한 시스템 컴포넌트들이 서로 로컬 콜 (call-by-reference)기반으로 타이트하게 연결되어 있기 때문에, 전체 시스템의 구조를 제대로 파악하지 않고 개발을 진행하면, 특정 컴포넌트나 모듈에서의 성능 문제나 장애가 다른 컴포넌트에까지 영향을 주게 되며, 이런 문제를 예방하기 위해서는 개발자가 대략적인 전체 시스템의 구조 등을 이해 해야 하는데, 시스템의 구조가 커질 수 록, 개인이 전체 시스템의 구조와 특성을 이해하는 것은 어려워진다. 특정 컴포넌트를 수정하고자 했을때, 컴포넌트 재 배포시 수정된 컴포넌트만 재 배포 하는 것이 아니라 전체 애플리케이션을 재 컴파일 하여 전체를 다시 통으로 재배포 해야하기 때문에 잦은 배포가 있는 시스템의 경우 불리하며, 컴포넌트 별로, 기능/비기능적 특성에 맞춰서 다른 기술을 도입하고자 할때 유연하지 않다. 예를 들어서, 전체 애플리케이션을 자바로 개발했다고 했을 때, 파일 업로드/다운 로드와 같이 IO 작업이 많은 컴포넌트의 경우 node.js를 사용하는 것이 좋을 수 있으나, 애플리케이션이 자바로 개발되었기 때문에 다른 기술을 집어 넣기가 매우 어렵다.
※ 모노리틱 아키텍쳐가 꼭 나쁘다는 것이 아니다. 규모가 작은 애플리케이션에서는 배포가 용이하고, 규모가 크더라도, call-by-reference call에 의해서 컴포넌트간 호출시 성능에 제약이 덜하며, 운영 관리가 용이하다. 또한 하나의 구조로 되어 있기 때문에, 트렌젝션 관리등이 용이하다는 장점이 있다. 즉 마이크로 서비스 아키텍쳐가 모든 부분에 통용되는 정답은 아니며, 상황과 필요에 따라서 마이크로 서비스 아키텍쳐나 모노리틱 아키텍쳐를 적절하게 선별 선택 또는 변형화 해서 사용할 필요가 있다.
- 마이크로 서비스 아키텍쳐
- 마이크로 서비스 아키텍쳐는 대용량 웹서비스가 많아짐에 따라 정의된 아키텍쳐인데, 그 근간은 SOA (Service Oriented Architecture : 서비스 지향 아키텍쳐)에 두고 있다. SOA는 엔터프라이즈 시스템을 중심으로 고안된 아키텍쳐라면, 마이크로 서비스 아키텍쳐는 SOA 사상에 근간을 두고, 대용량 웹서비스 개발에 맞는 구조로 사상이 경량화 되고, 대규모 개발팀의 조직 구조에 맞도록 변형된 아키텍쳐이다.
- 장점 1
- 단일체 소프트웨어에서는 코드 저장소로써 개발자는 오직 하나의 언어(예를들면 자바)로 개발합니다. 하지만 마이크로서비스에서는 각 서비스는 독립적이고 새로운 프로젝트이며 요구사항에 맞는 어떠한 언어든지 사용해서 개발될 수 있습니다.
- 장점 2
- 개발자는 오직 특정 서비스만 집중하기 때문에 코드 저장소는 매우 작을 것이고 개발자는 코드를 잘 알고 있을 것입니다.
- 장점 3
- 서비스가 다른 서비스와 통신할 필요가 있을때 API를 통해(구체적으로 REST 서비스에 의해) 서비스들은 통신할 수 있습니다. REST 서비스는 커뮤니키에션을 위한 중개자이기 때문에 매우 작은 변환만 있습니다. SOA와는 다르게 마이크로 서비스 메시지 버스는 아주 많은 변환, 분류, 라우팅을 하는 ESB보다 훨씬 더 얇습니다.
- 장점 4
- 중앙화된 데이터베이스가 없습니다. 각 모듈은 각자의 데이터베이스를 가지고 있기 때문에 데이터는 분산 되어있습니다. 개발자는 모듈에 따라 NoSQL 또는 관계형 데이터베이스를 사용할 수 있다는 사실은 전에 언급한 폴리글랏 퍼시스턴스를 데뷔시킵니다.
많은 사람들이 SOA와 마이크로서비스가 같은 것이라고 생각합니다. 정의에 따르면 같아 보이지만 SOA는 데이터를 관리하고 분류하는 등 많은 책임을 가진 ESB를 통해 서로 다른 시스템간에 통신을 위해 사용되었습니다. 하지만 마이크로서비스는 입력을 한 서비스에서 다른 서비스로 전송만하는 단순 메시지 버스(dumb message bus)를 사용하지만 메시지를 받는 엔드포인트(endpoint)는 전에 언급한 작업들을 할 수 있을 정도로 똑똑합니다. 마이크로서비스는 우둔한 메시지 버스를 가지고 있지만 똑똑한 엔드포인트가 있습니다. 마이크로 서비스는 REST를 통해 통신을 하며 변환 범위는 API를 통해 호출하는 다른 서비스에 의존하는 오직 하나의 서비스로 아주 작습니다. 하지만 마이크로서비스 또한 단점을 가지고 있습니다. 모든 기능적 특성은 개별 서비스이며 따라서 큰 프로젝트에는 많은 서비스들이 있습니다. 이러한 서비스들을 모니터링하는 것은 오버헤드를 증가시킵니다. 그뿐만이 아니라 서비스가 장애가 나는 경우 장애를 추적하는 것은 힘든 작업이 될 수 있습니다. 서비스는 다른 서비스를 호출하기 때문에 경로를 추적하고 디버깅하는 것 또한 어렵습니다. 각 서비스는 로그를 생성하기 때문에 중앙 로그 모니터링은 없습니다. 이는 매우 고통스러운 부분이며 장애를 대비해 아주 좋은 로그 관리 시스템을 필요로 합니다. 마이크로서비스에서는 각 서비스는 모놀리스 소프트웨어의 프로세스간 통신에 비해 좀 더 큰 오버헤드를 가진 API/원격 호출을 통해 통신합니다. 이러한 모든 결점에도 불구하고 마이크로서비스는 실제로 책임의 분리를 이뤄냅니다.
- 장점1. 각 모듈은 독립적이기 때문에 해당 모듈에 가장 잘 맞는 프로그래밍 언어를 선택할 수 있다.
- 장점2. 각 모듈마다 자신의 데이터베이스를 가지고 있기 때문에 제약없이 NoSQL 또는 관계형 데이터베이스를 선택할 수 있다. 따라서 애플리케이션도 전적으로 폴리글랏이다. (여러가지 언어로 개발하는 것, 여러 언어를 자유롭게)
장점3. 개발자는 마이크로서비스의 개발과 관리함으로 모듈에 대한 방대한 지식을 갖게 된다. 다기능 멤버들은 서비스를 위해 함께 일한다.
- 단점1. 서버는 다른 서버를 호출할 수 있기 때문에 큰 규모의 프로젝트에서는 서비스 호출을 추적하거나 서비스들을 모니터링하기 힘들다.
- 단점2. 하나의 서비스는 다른 서비스와 REST API를 통해 소통하기 때문에 단일체의 프로세스간 통신에 비해 느리다.
단점3. 디버깅이 힘들다. 서비스 호촐이 다른 서비스를 연속적으로 호출하는 경우에 특히 힘들다.
- 결론
- 개인적으로는 마이크로 서비스 아키텍처는 이미 기존 서비스 운영을 잘하고 있고, 장애 처리나 모니터링 등을 잘하고 있는 조직이 다음 단계로 진화하는 아키텍처로 선정하는 것이 좋다고 생각합니다. 처음부터 마이크로서비스 아키텍처를 선택하면 운영 및 관리의 헬에서 빠져 나오기 어렵고 그런 오버헤드가 마이크로서비스 아키텍처의 장점을 상쇄시킬 정도로 충분히 클 가능성이 높기 때문입니다. 그리고 초기 단일체 구조 아키텍처로 시작된 작은 서비스가 서비스가 복잡해지고, 조직도 커지고, 팀원의 역량은 충분히 높아졌으면 마이크로서비스 아키텍처로의 진화를 고려하는 것이 좋을 것 같습니다.
HTTP와 HTTPS의 차이점?
- HTTP
- HTTP 는 웹브라우저(Client)와 서버(Server)간의 웹페이지같은 자원을 주고 받을 때 쓰는 통신 규약
- HTTP는 HyperText Transfer Protocol의 약자로 클라이언트(정보 요청자)와 서버 사이에 이루어지는 프로토콜로 주로 HTML문서를 주고 받는데 사용되는 것으로 우리가 검색을 통해서 볼 수 있는 글이나 그림은 등이 http로 규정된 약속에 의해서 보게 된다.
- 하지만 HTTP는 클라이언트가 요청한 페이지를 암호화 되지 않은 상태로 주고 받을 수 있어 HTTP로 만든 홈페이지는 클라이언트와 서버의 네트워크에 침입 해 중간에서 정보를 가로챌 수 있는 위험이 상존한다.
- 정보를 마음대로 열람, 수정이 가능하다.
- HTTPS
- 인터넷 상에서 정보를 암호화하는 SSL(Secure Sockey Layer)프로토콜을 이용하여 웹브라우저(클라이언트)와 서버가 데이터를 주고 받는 통신 규약
- HTTPS의 S는 HTTP에 비해 달랑 한 글자 밖에 차이가 없지만 그 차이는 크다. S는 SSL(Secure Socket Layer)를 의미하는 것으로 주고 받는 정보가 암호화되어 있음을 뜻한다. 때문에 보안이 필요한 은행이나 쇼핑몰, 정부사이트 등에서 HTTPS로 된 홈페이지를 만들어 사용한다.
- HTTPS의 암호화는 클라이언트는 공개키를, 서버는 서버만 알 수 있는 개인키를 이용하는 방식이다. 즉 이용자(클라이언트)가 사이트에 접속하게 되면 서버가 공개키를 이용자에게 보내게 되고 이를 통해서 이용자의 암호화된 정보를 서버는 개인키로 볼 수 있어 네크워크에 침입한 해커는 아무것도 볼 수 없게 된다.
- HTTPS는 이러한 보안상의 장점이 있는 반면 암호화된 정보를 교환하기 때문에 서버가 과부하에 걸리는 경우가 발생하며, 접속이 끊기게 되면 다시 처음부터 시작해야 하는 불편함이 따른다. 이러한 불편함에도 빠른 속도와 다양한 기능을 제공하고 있는 구글은 우리나라 포털사이트와 달리 안전한 https로 만든 홈페이지를 운영하고 있어 비교된다.
- 네트워크 상에서 열람, 수정이 불가능하다.
- 모든 페이지에서 HTTPS를 사용하지 않는 이유
- SSL 인증서 구입 비용 및 갱신 비용이 발생한다.
- HTTP에 비해 서버에 부하가 더 많이 간다.(HTTP보다 속도가 느리다.)
HTTP 버전별로 설명
- HTTP/0.9
- HTTP의 초기 버전에는 버전 정보가 없었고 차후에 구분을 위해 0.9라고 불리게 되었다고 합니다. 아주 단순하게 GET 통신만 가능하고 이후에 버전에 존재하는 HTTP 헤더가 없기 때문에 전송은 HTML 문서만 가능하고 다른 유형은 전송할 수 없습니다. 또한 상태 혹은 오류 코드가 없기 때문에 문제의 상황시 해당 파일 내부에 문제에 대한 설명을 포함하여 보내졌다고 합니다.
- HTTP/1.0
- HTTP/1.0 에서는 상태코드가 응답값 시작 부분에 포함되어 요청에 대한 성공과 실패를 바로 확인할 수 있게 되었습니다. 그리고 위에 언급하였던 HTTP 헤더가 요청과 응답 모두에 추가되어 프로토콜의 확상이 가능해지고 헤더의 ‘Content-Type’의 도움으로 HTML 파일 이외의 다른 문서들도 전송이 가능하게 되었습니다. 또한 메서드 POST, HEAD가 추가되었습니다. (용어의 좁은 의미에서 공식적인 표준은 아니라고 합니다)
- HTTP/1.1
- HTTP/1.1은 HTTP의 첫번째 표준 버전입니다. 눈에 잘 보이는 추가점은 메서드에 OPTIONS, PUT, DELETE, TRACE 가 추가되었습니다. 그리고 헤더값도 몇가지 추가되었는데요, 역시 그 중에 조금 낯익은 부분들은 아래와 같습니다.
- Via : 중계서버(프록시, 게이트웨이 등)의 지원 프로토이름.버전.호스트명 (ex. via: 1.1 123abc.cloudfront.net (CloudFront))
Accept : 클라이언트의 사용가능 미디어타입 (ex. application/json, text/plain, /)
그리고 HTTP/1.1 에서는 성능향상을 위해 바뀐 부분이 몇가지 있는데요. 깊이 있게 알고 있진 않지만 대략 이야기를 해보자면, 이전 HTTP/1.0에서의 통신은 예를 들어, 같은 요청하는 서버(클라이언트 서버)와 응답해 줄 서버(API 서버)가 10개의 API 통신을 한다고 하면 연결(커넥션)을 맺고 그다음 리소스를 주고 받고 둘의 연결을 끊고를 10번 반복하게 됩니다. 그런데 HTTP/1.1 에서는 일정시간 클라이언트 서버와 API서버간의 연결 정보를 기억하여 반복적으로 일어나는 통신에 연결의 맺고 끊음을 줄였습니다.
위의 이야기는 쉽고 간단한 이해를 위한 글로 실제와 차이가 있을 수 있습니다…
- 그리고 파이프라이닝이라는 것이 추가되었는데요 이 역시 간단하게 이야기를 하면, 여러개의 요청이 있을때 이전의 요청이 완전히 전송되기 전에 다음의 요청을 전송을 가능하게하여 레이턴시를 낮추었다고 합니다. 쉽게 이야기를 하면… 전송받는데 1초가 걸리는 이미지 파일 10개 요청한다 했을때, 이전에는 1초씩 10번 걸려서 10초가 걸렸는데, 파이프라이닝이라는 것을 통해서 0.8초 쯤 다음 이미지를 요청하도록 해서 총 8초면 된다. 뭐 이런 이야기 같습니다.
- HTTP/2
- 사실은 앞선 이야기는 이것을 적기 위환 과정이었던 거 같아요. 우선 HTTP/2는 2010년 전반기에 구글이 실험적인 SPDY 프로토콜을 구현해서 클라이언트와 서버 간의 데이터 교환을 대체할 수단을 실증했다고 합니다. 그리고 그것이 HTTP/2의 기초로서 기여했다고 합니다.
HTTP/2 프로토콜은 HTTP/1.1 과 몇가지 근본적인 차이가 있는데요. 몇가지가 적혀있는데, 가장 핵심적인 부분은 HTTP/1.1이 텍스트 프로토콜이라면 HTTP/2는 이진 프로토콜이라는 점 같습니다.
하지만, 대략적으로 추측을 해보자면, 텍스트 형태의 리소스는 바이너리 형태에 비해 당연히 효율이 나쁠 것 같아요. 텍스트는 사람이 이해하기 좋을 뿐 컴퓨터는 어짜피 결론적으로 바이너리 형태로 이해할태니까요. 간추리면 브라우저에서 데이터를 바이너리 값으로 변환하여 서버로 보내고 서버는 그 바이너리 값을 해석하여 처리하겠죠? ‘Google ? Web Fundamentals’의 문서를 참고하면 아래와 같이 데이터를 바이너리 프레이밍 값으로 캡슐화하여 주고 받는 것 같습니다.
1
2
3
4
5
6
7
# HTTP 1.1
POST /upload HTTP/1.1
Host: www.example.org
Content-Type: application/json
COntent-Length: 15
...✂...
{"msg": "hello"}
1
2
3
# HTTP 2.0
HEADER frame
DATA frame
- 그리고 이러한 바이너리 프레이밍 구조가 이후에 나오게 될 HTTP2의 특징이나 장점에 기본이 되는 부분인 것 같습니다. 저의 지식이 얕기 때문에 프로토콜의 원리에 대해 이해하고 이야기하는 것은 어려울 것 같고 간단하게 특징을 적어보려합니다.
4-1. 요청 및 응답 다중화
- HTTP/1.1 에서는 한번에 커넥션을 맺고 데이터를 요청하고 응답받고를 반복하는데요, HTTP/2에서는 스트림(stream)으로 한번의 커넥션으로 동시에 여러개의 데이터를 주고 받을 수 있습니다. 이렇게 하여 HTTP/1.x 에서의 이미지 스프라이트, 도메인 분할 같은 임시방편을 사용하지 않아도 됩니다.
4-2. 스트림 우선 순위
- 위와 같이 스트림의 프레임으로 다중화가 가능해짐과 동시에 클라이언트와 서버의 통신 순서를 위해 각 스트림에는 1~256 사이의 정수 가중치가 할당되어 스트림 처리 우선순위를 정합니다. 그런데 이게 우선 순위를 지정하여 이를 처리할 CPU, 메모리 및 기타 리소스의 할당을 제어하는 것일 뿐 특정 순서로 처리되도록 서버에 강요될 수 없다고 합니다.
- HTTP도 TCP 위에서 돌아가는데… 이 부분은 좀 더 공부해야 이해할 수 있을 것 같습니다.
4-3. 헤더 압축
- HTTP/1.x의 경우에는 가령 두개의 동일한 요청을 보낸다고 했을때, 두개의 헤더에 중복값이 존재해도 모두 전송하는데요, HTTP/2에서는 HPACK 압축형식을 사용해서 요청 및 응답 헤더 메타데이터를 압축하는데 이때 이 중복되는 헤더값을 색인값으로 처리해준다고 합니다.
JAVA
- JAVA는 네트워크상에서 쓸 수 있도록 미국의 선 마이크로 시스템즈가 개발한 객체 지향 프로그래밍 언어
- Java의 특징
- 자바가상머신(JVM)만 설치하면 컴퓨터의 운영체제의 상관없이 작동한다.(즉, 운영체제에 독립적)
- 기본 자료형을 제외한 모든 요소들이 객체로 표현
- 객체 지향 개념의 특징인 캡슐화, 상속, 다형성이 잘 적용된 언어
- 메모리를 자동으로 관리한다
- C++이 메모리 관리를 위해 개발자가 직접 코드를 작성해야 하는 반면, 자바는 개발자가 메모리에 직접 접근할 수 없으며 자바가 직접 메모리를 관리한다. 객체를 생성할 때 자동적으로 메모리 영역을 찾아서 할당하고, 사용이 완료되면 Garbage Collector를 실행시켜 자동적으로 사용하지 않는 객체를 제거한다. 따라서 개발자는 메모리 관리의 수고스러움을 덜고, 코딩에 좀 더 집중할 수 있다.
- 멀티쓰레드(Multi-thread)를 지원
- 자바는 스레드 생성 및 제어와 관련된 라이브러리 API를 제공하고 있기 때문에 실행되는 운영체제에 상관없이 멀티 스레드를 쉽게 구현할 수 있다.
- 동적 로딩(Dynamic Loading)을 지원한다
- 애플리케이션이 실행될 때 모든 객체가 생성되지 않고, 각 객체가 필요한 시점에 클래스를 동적 로딩해서 생성한다. 또한 유지보수 시 해당 클래스만 수정하면 되기 때문에 전체 애플리케이션을 다시 컴파일할 필요가 없다. 따라서 유지보수가 쉽고 빠르다.
- 이식성이 높은 언어이다
- 이식성이란 서로 다른 실행 환경을 가진 시스템 간에 프로그램을 옮겨 실행할 수 있는 것을 말한다. 자바 언어로 개발된 프로그램은 소스 파일을 수정하지 않아도, 자바 실행 환경(JRE)이 설치되어 있는 모든 운영 체제에서 실행 가능하다.
JAVA의 JVM이란?
- JVM이란 Java Virtual Machine, 자바 가상 머신의 약자를 따서 줄여 부르는 용어이다. (가상머신이란 프로그램의 실행하기 위해 물리적 머신과 유사한 머신을 소프트웨어로 구현한 것이다.) JVM 역할은 자바 애플리케이션을 클래스 로더를 통해 읽어 들여 자바 API와 함께 실행하는 것이다. 그리고 JVM은 JAVA와 OS사이에서 중개자 역할을 수행하여 JAVA가 OS에 구애받지 않고 재사용을 가능하게 해준다. 그리고 가장 중요한 메모리관리, Garbage Collection을 수행한다. 그리고 JVM은 스택기반의 가상머신이다. ARM 아키텍쳐 같은 하드웨어는 레지스터 기반으로 동작하는데 비해 JVM은 스택기반으로 동작한다.
Java 프로그램의 실행 과정
- 프로그램이 실행되면 JVM은 OS로부터 프로그램이 필요로 하는 메모리를 할당받는다. JVM은 이 메모리를 용도에 따라 여러 영역으로 나누어 관리한다.
- Java 컴파일러(javac)가 Java 소스코드(.java)를 읽어들여 Java 바이트코드(.class)로 변환시킨다.
- Class Loader를 통해 .class파일들을 JVM으로 로딩한다.
- 로딩된 class파일들은 Execution Engine을 통해 해석된다. -> 클래스 로딩이 끝나면 JVM은 main메소드를 찾아 지역변수, 객체변수, 참조변수를 스택에 쌓는다.
- 해석된 바이트코드는 Runtime Data Areas에 배치되어 실질적인 명령어 수행이 이루어지게 된다(CPU).
- 위와 같은 과정 속에서 JVM은 필요에 따라 Thread Synchronization과 GC같은 관리작업을 수행한다.
JVM 내부 모듈의 역할
- ClassLoader
- JVM내로 클래스들을 Load하고, Link를 통해 배치하는 작업을 수행하는 모듈로써, 런타임시 동적으로 클래스를 로드한다.
- Excution Engine
- ClassLoader를 통해 배치된 바이트코드를 명령어 단위로 실행한다.
- Garbage Collector
- 메모리 관리 기능을 자동으로 수행한다. 애플리케이션이 생성한 객체의 생존 여부를 판단하여 더 이상 사용되지 않는 객체를 해제한다.
- Runtime Data Areas
- JVM이 운영체제 위에서 실행되면서 할당받는 메모리 영역이다. ClassLoader에서 준비한 데이터들을 보관하는 저장소
- PC 레지스터: 쓰레드마다 현재 수행중인 JVM 명령의 주소를 갖는다.
- 스택 영역: 메소드가 호출될 때 마다 각각의 스택 프레임이 생성되며 메소드안에서 사용되는 local variables를 저장한다.
- 메소드 영역: 클래스 정보를 처음 메모리 공간에 올릴 때 초기화되는 대상(바이트코드)을 저장하기 위한 메모리 공간이다. Runtime Constant Pool이라는 영역도 함께 존재하는데, 상수 자료형을 저장하여 참조하고 중복을 막는 역할을 수행한다.
- 힙 영역: 객체를 저장하는 가상 메모리 공간이다. new 연산자로 생성된 객체와 배열을 저장한다. 힙영역에 생성되는 객체는 자동 초기화됨.
JAVA 제네릭(Generics)
- 타입인수를 사용해 일반화된 클래스나 메소드를 정의하는 기법
- 메소드의 인자값으로 들어가는 타입만 달라질 뿐 하는 동작이 똑같다면, 여러 타입의 인자가 들어갈 경우에 대해 일일히 명시적으로 인자값을 지정 함수를 오버로딩 하는 방법이 있다. 하지만 제네릭을 이용해 한 번만 구현해놓고 <> 안에 사용 타입을 지정함으로써, 재사용성, 형식 안정성 및 효율성을 달성할 수 있다.
JAVA 컬렉션(Collection)
Java Collections Framework(JCF)
- Java에서 컬렉션(Collection)이란 데이터의 집합, 그룹을 의미하며 JCF(Java Collections Framework)는 이러한 데이터, 자료구조인 컬렉션과 이를 구현하는 클래스를 정의하는 인터페이스를 제공한다.
- 다음은 JCF의 상속 구조를 나타낸다.
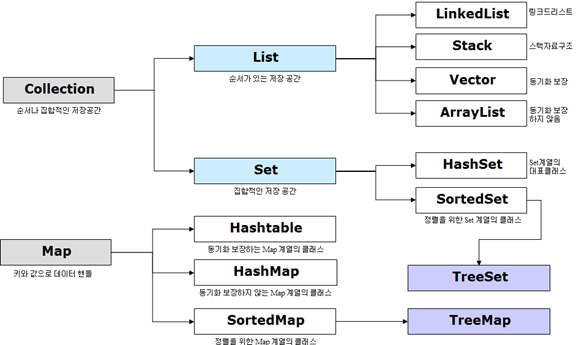
- Collection 인터페이스는 List, Set, Queue로 크게 3가지 상위 인터페이스로 분류할 수 있다.
- Map의 경우 Collection 인터페이스를 상속 받고 있지 않지만 Collection으로 분류된다.
Collection 인터페이스의 특징
| 인터페이스 | 구현클래스 | 특징 |
|---|---|---|
| Set | HashSet, TreeSet | 순서를 유지하지 않는 데이터의 집합으로 데이터의 중복을 허용하지 않는다. |
| List | LinkedList, Vector, ArrayList | 순서가 있는 데이터의 집합으로 데이터의 중복을 허용한다. |
| Queue | LinkedList, PriorityQueue | List와 유사 |
| Map | Hashtable, HashMap, TreeMap | 키(Key), 값(Value)의 쌍으로 이루어진 데이터의 집합으로, 순서는 유지되지 않으며 키(Key)의 중복을 허용하지 않으나 값(Value)의 중복은 허용한다. |
- Set 인터페이스
- 순서를 유지하지 않는 데이터의 집합으로 데이터의 중복을 허용하지 않는다.
- HashSet
- 가장 빠른 임의 접근 속도
- 순서를 예측할 수 없음
- TreeSet
- 정렬 방법을 지정할 수 있음
- List 인터페이스
- 순서가 있는 데이터의 집합으로 데이터의 중복을 허용한다.
- LinkedList
- 양방향 포인터 구조로 데이터의 삽입, 삭제가 빈번할 경우 데이터의 위치 정보만 수정하면 되기에 유용
- 스택, 큐, 양방향 큐 등을 만들기 위한 용도로 쓰임
- Vector
- 과거에 대용량 처리를 위해 사용했으며, 내부에서 자동으로 동기화 처리가 일어나 비교적 성능이 좋지 않고 무거워 잘 쓰이지 않음
- ArrayList
- 단방향 포인터 구조로 각 데이터에 대한 인덱스를 가지고 있어 조회 기능에 성능이 뛰어남
- Map 인터페이스
- 키(Key), 값(Value)의 쌍으로 이루어진 데이터의 집합으로, 순서는 유지되지 않으며 키(Key)의 중복을 허용하지 않으나 값(Value)의 중복은 허용한다.
- Hashtable
- HashMap보다는 느리지만 동기화 지원
- null 불가
- HashMap
- 중복과 순서가 허용되지 않으며 null 값이 올 수 있다.
- TreeMap
- 정렬된 순서대로 키(Key)와 값(Value)을 저장하여 검색이 빠름
Garbage Collection(가비지 컬렉션)
- 시스템에서 더이상 사용하지 않는 동적 할당된 메모리 블럭을 찾아 자동으로 다시 사용 가능한 자원으로 회수하는 것으로 시스템에서 가비지 컬렉션을 수행하는 부분을 가비지 컬렉터라 부른다.
Jquery, Ajax, Json?
- jQuery : javascript 기반으로 만들어진 라이브러리
- JSON : 인터넷에서 자료를 주고받을때 쓰는 문법
- ajax : 비동기로 화면깜박임 없이 데이터를 주고받는 방법
Primitive type과 Reference type
- Primitive type : 변수에 값 자체를 저장.
- 정수형 : byte, short, int, long
- 실수형 : float, double
- 문자형 : char
- 논리형 : boolean
- Primitive type은 Wrapper Class를 통해 객체로 변형할 수 있다.
- 예) int->Integer, char->Character(int와 char르 제외한 Primitive type의 다른 자료형들은 맨 앞 알파벳을 대문자로 바꿔주면 된다. float->Float)
- Reference type : 메모리상에 객체가 있는 위치를 저장.
- 종류 : Class, Interface, Array 등
Wrapper Class
- Primitive type으로 표현할 수 있는 간단한 데이터를 객체로 만들어야 할 경우가 있는 그러한 기능을 지원하는 클래스.
OOP(객체지향 프로그래밍)
- OOP란 Object-Oriented Programming의 약어로써 객체지향 프로그래밍을 의미
- 데이터를 객체로 취급하여 프로그램에 반영한 것이며, 순차적으로 프로그램이 동작하는 기존의 것들과는 다르게 객체와 객체의 상호작용을 통해 프로그램이 동작하는 것을 말한다.
- OOP 특징
- 객체지향 프로그래밍은 코드의 재사용성이 높다.
- 코드의 변경이 용이
- 직관적인 코드 분석
- 개발속도 향상
- 상속을 통한 장점 극대화
Object
- Object(객체)는 OOP에 데이터(변수)와 그 데이터에 관련되는 동작(함수). 즉 절차, 방법, 기능을 모두 포함한 개념.
소켓 통신(TCP/UDP)
- TCP(Transmission Control Protocol)
- 연결형 서비스 제공
- 높은 신뢰성 보장
- 연결의 설정(3-way handshaking)
- 연결의 해제(4-way handshaking)
- 데이터 흐름 제어, 혼잡 제어
- 전이중, 점대점 서비스(양방향 송수신 서비스)
- UDP(User Datagram Protocol)
- 비연결형 서비스 제공
- 신뢰성이 낮음
- 데이터의 전송 순서가 바뀔 수 있음
- 데이터 수신 여부 확인 안함(3-way handshaking과 같은 과정 X)
- TCP보다 전송속도가 빠름
웹 서버와 WAS(Web Application Server)의 정의
- 웹 서버와 WAS는 비슷한 개념이기 때문에 같이 또는 다르게 사용되는 단어 가운데 하나이다. 인터넷 확산 초기에는 웹 서버라는 개념으로 통칭해서 사용했지만, 시간이 지남에 따라 WAS를 더 많이 사용하고 있다. 인터넷 사용자가 증가함에 따라, 각 웹 사이트는 보다 많은 사용자에게 원활한 서비스를 제공하기 위해 기능적인 layer를 나우게 되었고 여기서 웹 서버와 WAS의 구분점이 생기게 된 것이다.
- 기능적으로만 본다면, 거의 대부분의 웹 서버가 웹 애플리케이션을 동작시킬 수 있겠지만 모두 웹 서버 혹은 WAS라고 부르는 것보다는 어떤 기능을 수행하는지에 따라, 즉 기능상의 분류를 통해 구분지어 사용해야 할 것이다.
- WAS와 웹 서버의 차이점 : 동적 컨텐츠 처리를 수행 가능한가 아닌가. WAS는 정적, 동적 처리 둘다 가능하지만 정적 처리를 WAS가 하게 되면 부하가 많이 걸려서 좋지 않다.
- 웹 서버
- 웹브라우저(Web Client)에게 컨텐츠를 제공하는 서버. 즉, 정적인 HTML이나 jpeg, gif 같은 이미지를 HTTP 프로토콜을 통해 웹 브라우저에 제공한다.
- 최근에는 웹 서버에서도 내부 애플리케이션을 동작시킬 수 있는 컨테이너를 내장하고 있다.
- WAS
- 서버단에서 애플리케이션을 동작할 수 있도록 지원한다.
- 일반적으로 컨테이너라는 용어로 쓰인다.
- 초장기에는 CGI, 그 이후에는 Servlet, ASP, JSP, PHP 등의 프로그램으로 사용되고 있다.
- 웹 서버
Database에서 Index란?
- 인덱스는 데이터베이스 분야에 있어서 테이블에 대한 동작의 속도를 높여주는 자료 구조를 일컫는다. 인덱스는 테이블 내의 1개의 컬럼, 혹은 여러 개의 컬럼을 이용하여 생성될 수 있다. 고속의 검색 동작뿐만 아니라 레코드 접근과 관련 효율적인 순서 매김 동작에 대한 기초를 제공한다. 인덱스를 저장하는 데 필요한 디스크 공간은 보통 테이블을 저장하는 데 필요한 디스크 공간보다 작다. 데이터베이스에서 테이블과 클러스터에 연관되어 독립적인 저장 공간을 보유하고 있는 객체(object)이다. 사용자는 데이터베이스에 저장된 자료를 더욱 빠르게 조회하기 위하여 인덱스를 생성하고 사용한다.
- DB에서 자료를 검색하는 두 가지 방법
- FTS(Full Table Scan) : 테이블을 처음부터 끝까지 검색하는 방법.
- Index Scan : 인덱스를 검색하여 해당 자료의 테이블을 액세스하는 방법.
DB의 옵티마이저란?
- 사용자가 요청한 SQL 을 가장 효율적이고 빠르게 수행할 수 있는 최적의 처리경로를 선택해 주는 DBMS 의 핵심엔진
로그를 남기는 이유, 로그를 남기지 말아야 할 데이터
- 로그는 표시다. 로직의 흐름이나, 문제점이나, 오작동여부를 확인하는 데 도움을 주기 때문이다. 로그를 남기는 이유는 로직이 의도된 바로 흐르는지, 내 코드의 문제나 내 코드를 잘못 사용한 코드가 없는지를 감지하기 위해서다.
- 로그 처리와 관련해 가장 좋은 모범 사례 중 하나는 운영 모드에서는 불필요한 로그를 꺼두는 것입니다. 디스크 IO는 매우 비싼 작업이기 때문입니다. 불필요한 로그를 켜두는 것은 잦은 디스크 IO를 발생시켜 애플리케이션을 느리게 할 뿐 아니라, 확장성에도 심각한 영향을 미칠 수 있습니다. 로그를 디스크에 남기려면 많은 디스크 공간이 필요하며, 디스크 공간이 고갈되면 애플리케이션도 다운됩니다. 로깅 프레임워크는 어떤 로그를 남기고 어떤 로그를 남기지 말아야 할지 런타임에 제어할 수 있는 옵션을 제공합니다. 대부분의 로깅 프레임워크는 세밀한 수준의 로깅 제어 기능을 제공하며, 로깅 관련 설정을 런타임에 변경할 수 있는 옵션을 제공합니다.
- 반대로 로그는 중요한 정보를 담고 있기도 하므로 적절히 분석한다면 높은 가치의 정보를 얻을 수도 있습니다. 그래서 로그 남기는 것을 제한하면 애플리케이션의 동작을 이해하는 데 방해가 되는 것도 사실입니다.
비동기와 동기 방식의 차이점?
- 동기(synchronous : 동시에 일어나는)
- 동기는 말 그대로 동시에 일어난다는 뜻입니다. 요청과 그 결과가 동시에 일어난다는 약속인데요. 바로 요청을 하면 시간이 얼마가 걸리던지 요청한 자리에서 결과가 주어져야 합니다.
- 요청과 결과가 한 자리에서 동시에 일어남
- A노드와 B노드 사이의 작업 처리 단위(transaction)를 동시에 맞추겠다.
- 동기는 말 그대로 동시에 일어난다는 뜻입니다. 요청과 그 결과가 동시에 일어난다는 약속인데요. 바로 요청을 하면 시간이 얼마가 걸리던지 요청한 자리에서 결과가 주어져야 합니다.
- 비동기(Asynchronous : 동시에 일어나지 않는)
- 비동기는 동시에 일어나지 않는다를 의미합니다. 요청과 결과가 동시에 일어나지 않을거라는 약속입니다.
- 요청한 그 자리에서 결과가 주어지지 않음
- 노드 사이의 작업 처리 단위를 동시에 맞추지 않아도 된다.
- 비동기는 동시에 일어나지 않는다를 의미합니다. 요청과 결과가 동시에 일어나지 않을거라는 약속입니다.
- 동기와 비동기는 상황에 따라서 각각의 장단점이 있습니다.
- 동기방식은 설계가 매우 간단하고 직관적이지만 결과가 주어질 때까지 아무것도 못하고 대기해야 하는 단점이 있고, 비동기방식은 동기보다 복잡하지만 결과가 주어지는데 시간이 걸리더라도 그 시간 동안 다른 작업을 할 수 있으므로 자원을 효율적으로 사용할 수 있는 장점이 있습니다.
VSS, CVS, SVN, Git
| 구분 | CVS | SVN |
|---|---|---|
| 커밋단위 | 지원 | 체인지 셋(Change set) |
| 원자적 커밋(커밋 실패 시 롤백) | 미지원 | 지원 |
| 처리 속도 | 느림 | 빠름 |
| 파일과 Directory의 삭제, 이동, 이름 변경, 복사 | 미지원 | 지원 |
| 소스코드외 이진파일(문서, 라이브러리 등) 지원 | 미지원 | 지원 |
| GUI(Graphic User Interface) 지원여부 | 지원 | 지원 |
| 웹 인터페이스(Web Interface) 지원여부 | 지원 | 지원 |
- VSS
- 설명 : VSS는 ‘Visual SourceSafe’의 약자로써 버전관리 소프트웨어이다. One Tree Software라는 회사에 의해 16비트용 응용프로그램(ver3.1)으로 처음 만들어졌다. 그 시절 Microsoft에도 ‘Delta’라는 이름의 버전관리 소프트웨어가 있었으나, 그 기능과 성능이 VSS만 못했으므로 1994년 Microsoft는 One Tree Software를 인수하여 1995년 32비트용 응용프로그램의 첫 버전인 VSS 4.0을 출시한다. 가장 최근 버전으로는 Visual Source Safe 2005가 있다.
- 장점
- Microsoft사의 제품이기 때문에 Microsoft의 솔루션들과의 통합이 아주 용이하다.
- Windows기반이기 때문에 설치와 사용이 그다지 어렵지 않다.
- 동시 수정이 불가능하여 작업의 충돌이 일어나지 않는다.(단점이기도 함) * 단점
- VSS의 직접적인 파일기반 접근 메카니즘은 어떤 클라이언트든 저장소안의 파일을 잠금(Locking)후에 수정하는 것을 허락하기 때문에 만약 파일을 업데이트 하는 도중 클라이언트의 PC에 충돌이 일어나기라도 하면 파일이 손상된 상태로 남겨질 수 있다.(잦은 저장소 손상)
- 파일이 누군가에 의해 수정중인(Locking) 경우 파일에 접근하지 못함.(동시 수정 불가능)
- 대규모 프로젝트에는 부적합하며, 소규모(5명) 프로젝트인 경우에 적합하다. (대규모 프로젝트에는 Microsoft사의 ‘Team Foundation Server’ 사용)
- 가지치기(Branch) 기능이 빈약하다.
- CVS
- 설명 : CVS는 ‘Concurrent Versions System’의 약자로써 버전관리 소프트웨어이다. 소프트웨어 개발 프로젝트에서 파일 단위의 모든 작업과 모든 변화를 추적하고 여러 개발자(지역적으로 떨어진)가 협력하여 작업할 수 있도록 지원한다. CVS는 GNU 라이선스하에서 배포되며 오픈 소스 프로젝트에서 널리 사용된다. 현재는 설계상 몇가지 크고 작은 문데들로 인해 Sub version(SVN)에게 그 자리를 내어주고 있는 추세이다.
- 장점
- CVS는 오랜기간에 걸쳐 많은 사용자들을 확보한 안정되고 검증된 버전관리 소프트웨어이다.
- 하나의 파일에 대한 동시작업이 가능하다.
- 병합(merge), 가지치기(branch), 태그(tag), 비교(compare) 기능을 지원한다.
- Unix, Linux, Windows 등 대부분의 운영체제를 지원한다.
- 파일 전체를 저장하는 것이 아니라 변경사항만을 저장함으로 백업용량을 적게 차지한다. * 단점
- CVS 저장소의 파일들은 이름을 바꿀 수 없다. 제거하고 나서 다시 추가해야 한다.
- CVS 프로토콜은 디렉터리의 이동이나 이름 변경을 허용하지 않는다. 서브 디렉터리의 파일은 모두 지우고 다시 추가해야 한다.
- 아스키 코드로 된 파일 이름이 아닌 유니코드 파일을 제한적으로 지원한다.
- 속도가 느리다.
- 커밋 실패 시 롤백이 지원되지 않는다.
- VSS와 비교했을 경우 저장소가 다소 지저분하다.(‘CVS’ Directory들로 인해)
- SVN
- 설명 : SVN은 ‘Subversion’의 약자로써 버전관리 소프트웨어이다. 명령행 인터페이스에서 사용하는 명령어를 따서 ‘SVN’이라고 줄여서 부르기도 하며, CVS의 단점을 보완하기 위해 만들어졌다.
- 장점
- 원자적 커밋을 지원하므로 다른 사용자의 커밋과 엉키지 않으며, 실패 시 롤백 기능을 지원한다.
- 파일과 Directory의 삭제, 이동, 이름변경, 복사 등을 지원한다.
- 소스 파일 이외에 이진파일도 효율적으로 저장할 수 있다.
- Directory도 버전 관리를 할 수 있다. Directory 전체를 빠르게 옮기거나 복사할 수 있으며, 리비전 기록도 그대로 유지한다.
- 저장소의 크기에 상관없이 일정한 시간 안에 가지치기나 태그를 할 수 있다.
- 처리 속도가 빠르다. * 단점
- 안정성에 있어선 아직까진 CVS에 미치지 못함.
- VSS와 비교했을 경우 저장소가 다소 지저분하다.(‘.svn’ Directory들로 인해)
- 잦은 커밋으로 인해 리비전 번호의 인플레이션(inflation)이 유발될 수 있다.
- 소스코드는 Diff를 통해 병합(Merge)이 가능하지만 이진파일은 어느 한쪽을 버릴 수 밖에 없다.
- Git
- 설명 : 프로그램 등의 소스 코드 관리를 위한 분산 버전 관리 시스템.
- 지향점
- 빠른 수행 속도에 중점.
- 네트워크에 접근하거나 중앙 서버에 의존하지 않음.
- 작업 폴더는 모두, 전체 기록과 각 기록을 추적할 수 있는 정보를 포함한 완전한 형태의 저장소.
변수 명명법
- 카멜 표기법
- Java를 하는 사람들에게 가장 익숙한 표기법이 바로 카멜 표기법
- 기본적으로 변수를 소문자로 선언하는데, 두 단어 이상 이어진 변수는 첫 단어를 뺀 나머지 단어의 시작 부분을 대분자로 표기
- 낙타의 등을 닮았다고 해서 붙여진 이름
1 2 3
var busan; var appStore; var javaWebProgramming;
- 파스칼 표기법
- C 계열에 익숙한 사람들이 많이 사용했을 표기법
- 카멜 표기법과 유사하지만 유일한 차이점으로 모든 단어를 대분자로 표기
1 2 3
var Pascal; var BlackCherry; var RedAndBlue;
- 헝가리안 표기법
- 잘 안 쓰이는 표기법이지만 간혹가다 오래전에 짠 코드에서 가끔씩 발견되는 표기법
- 변수의 앞에 자료형을 붙여서 명명하는 방식
1 2 3
var strText; var intNumber; var arrBook;
64bit와 32bit 차이점?
- CPU는 외부에서 들어오는 데이터 처리능력이 있다. 한번에 처리하는 데이터가 32bit라면 32bit, 64bit CPU는 한번에 64bit 처리가 가능하다.
- 32bit로 메모리 공간을 표현한다면 최대 4Gbyte이다. 64bit라면 더 넓은 메모리 공간을 표현할 수 있는 것이다. 64bit를 사용하면 현재 보통 시스템에서는 128GB RAM과 1TB 페이징 스페이스를 사용할 수 있습니다.
- 즉 64bit는 메모리의 확장을 통해 보다 많은 프로그램을 한번에 돌리는 것이 수월해 진다는 장점을 가지고 있습니다. 하지만 32bit에서 64bit로 변경시 2배의 속도증가를 체감할 수 있는 것은 아니다. 단순히 CPU와 메모리만으로 PC가 구동되는 것이 아니기 때문에 Disk나 VGA등 여러 구성요소에 병목이 존재하기 때문이다.
- 만약 32bit컴퓨터의 주소값을 64bit로 표현하기로 하였다면 최소 주소공간은 2의 64승 개 만큼 넓어지나 CPU에서 처리를 위해서는 주소값을 2번에 걸쳐 전송이 이루어져야 하고 최소 2번 이상의 연산과정이 필요하다.